SnowPro Advanced Data Engineer Practice Exam — Free Online Test
QuestionQ1
Implement Data Pipelines
Save question
A company wants to obtain data from a Snowflake Marketplace provider for data-enrichment purposes. A Data Engineer must build a data pipeline that blends existing data in the company’s account with the provider’s data, including some transformations. The provider’s data is unavailable in the region where the company account is located.
How can the Data Engineer make the data available to the company for processing?
ACreate a new reader account in the region where the provider’s data is available and set up a transformation job to unload transformed data into a stage. Set up a copy job between this stage and the company’s stage and then ingest data into the company’s account to blend with any existing data.
BCreate a new reader account in the region where the provider’s data is available and set up a COPY job to unload data into a stage. Set up a data copy job between this stage and the company’s stage. Then ingest the data into the company’s account to transform and blend it with any existing data.
CCreate a new account in the region where the provider’s data is available. Get data from the Marketplace, and create a share to the company’s account. Then build a data pipeline to blend and transform the data.
DCreate a new account in the region where the provider’s data is available. Get data from the Marketplace and replicate the data to the company’s account. Then build a data pipeline to blend and transform the data.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Transform Data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Ingest and Process Data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ4
Ingest and Process Data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ5
Implement Data Protection and Recovery
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
Ingest and Process DataImplement Data PipelinesTransform DataDesign and Manage Snowflake Resources and PerformanceImplement Data Protection and Recovery
How can the following relational data be converted into semi-structured data with the least operational overhead?
AUse the TO_JSON function.
BUse the PARSE_JSON function to produce a VARIANT value.
CUse the OBJECT_CONSTRUCT function to return a Snowflake object.
DUse the TO_VARIANT function to convert each of the relational columns to VARIANT.
Which command successfully loads data into the table named finance_dept_location?
Acopy into finance_dept_location(city, zip, sale_date, price)from (select t.$1, t.$2, t.$3, t.$4 from @finstage/finance.csv.gz t) file_format = (format_name = fincsvformat);
Bcopy into finance_dept_location(city, zip, sale_date, price)from (select t.$1, t.$2, t.$3, t.$4 from @finstage/finance.csv.gz t) file_format = (format_name = fincsvformat) validation_mode=return_all_errors;
Ccopy into finance_dept_location(city, zip, sale_date, price)from (select t.$1, t.$2, t.$3, t.$4 from @finstage/finance.csv.gz t limit 100) file_format = (format_name = fincsvformat);
Dcopy into finance_dept_location(city, zip, sale_date, price)from (select t.$1, t.$2, t.$3, t.$4 from @finstage/finance.csv.gz t where t.$1 like '%austin%') file_format = (format_name = fincsvformat);
When loading data from a CSV file with SnowSQL, which copy option removes the header record from the data being loaded?
ASKIP_HEADER = 0
BSKIP_HEADER = 1
CPARSE_HEADER = TRUE
DPARSE HEADER = FALSE
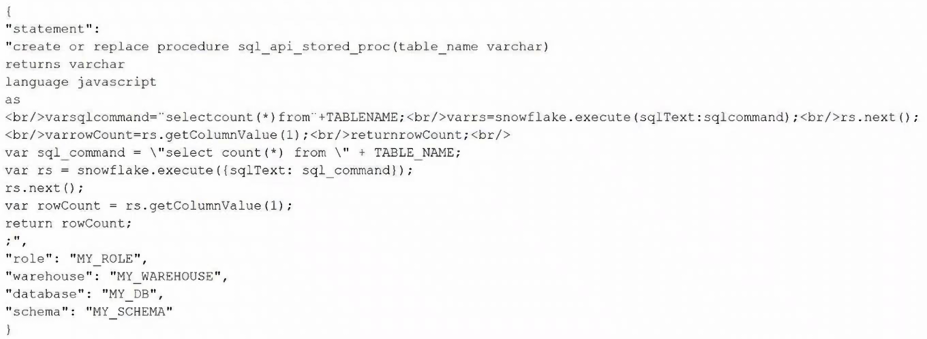
A Data Engineer is designing a Snowflake SQL API for calling a stored procedure with the following code:
When a request is sent, it must be authenticated.
Which authentication techniques meet this requirement?
Choose two
AMulti-Factor Authentication (MFA)
BOAuth
CKey-pair authentication
DSingle Sign-On (SSO) through a web browser
ENative Single Sign-On through Okta
QuestionQ6
Transform Data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ7
Transform Data
QuestionQ8
Ingest and Process Data
QuestionQ9
Ingest and Process Data
QuestionQ10
Design and Manage Snowflake Resources and Performance
QuestionQ11
Implement Data Protection and Recovery
QuestionQ12
Implement Data Pipelines
QuestionQ13
Implement Data Protection and Recovery
QuestionQ14
Implement Data Protection and Recovery
QuestionQ15
Design and Manage Snowflake Resources and Performance
QuestionQ16
Ingest and Process Data
QuestionQ17
Design and Manage Snowflake Resources and Performance
QuestionQ18
Implement Data Protection and Recovery
QuestionQ19
Design and Manage Snowflake Resources and Performance
QuestionQ20
Ingest and Process Data
QuestionQ21
Implement Data Protection and Recovery
QuestionQ22
Implement Data Protection and Recovery
QuestionQ23
Implement Data Protection and Recovery
QuestionQ24
Implement Data Pipelines
QuestionQ25
Design and Manage Snowflake Resources and Performance
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
A Data Engineer is creating a User-Defined Table Function (UDTF) with Snowpark Python using this code:
What will this UDTF do?
AIt will use Snowflake libraries to write the metadata from a file and return it in a table.
BIt will register a temporary User-Defined Function (UDF) that will read a text file from a stage using SnowflakeFile and will return the file length.
CIt will use SnowflakeFile to create an interface that will extract the contents of a CSV file and return the rows in a table.
DIt will use SnowflakeFile to extract a list of files that will be stored in an internal stage as a table.
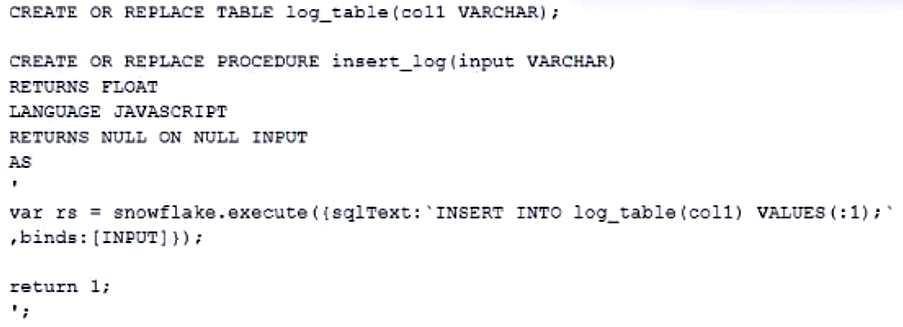
A database contains a table and a stored procedure defined as follows:
The log_table is initially empty, and a Data Engineer runs this command:
CALL insert_log(NULL::VARCHAR);
No other operations affect the log_table. What is the outcome of this procedure call?
AThe log_table contains zero records and the stored procedure returned 1 as a return value.
BThe log_table contains one record and the stored procedure returned 1 as a return value.
CThe log_table contains one record and the stored procedure returned NULL as a return value.
DThe log_table contains zero records and the stored procedure returned NULL as a return value.
Which isolation level do Snowflake streams use?
ASnapshot
BRepeatable read
CRead committed
DRead uncommitted
A Data Engineer wants to define a file structure for loading and unloading data.
Where can the file structure be defined?
Choose three
ACOPY command
BMERGE command
CFILE FORMAT object
DPIPE object
ESTAGE object
FINSERT command
A Data Engineer must optimize performance and reduce the costs of a Snowflake dynamic-table pipeline. The Engineer wants to monitor and isolate dynamic-table costs before moving the table-refresh processing to a shared virtual warehouse.
How should the Engineer satisfy these requirements?
AUse a shared virtual warehouse to test the performance of the dynamic table refresh process and monitor the costs for all workloads.
BBefore moving the table, test the process on a dedicated virtual warehouse to establish a cost baseline.
CExecute the dynamic tables on multiple virtual warehouses simultaneously to distribute the load equally.
DSet up the dynamic tables directly on a production virtual warehouse to obtain real-time cost insights.
A Data Engineer ran a stored procedure that contained various transactions. While it was executing, the session abruptly disconnected, preventing one transaction from committing or rolling back. The transaction remained in a detached state and placed a lock on resources.
What must the Engineer do to immediately run a new transaction?
ACall the system function SYSTEM$ABORT_TRANSACTION.
BCall the system function SYSTEM$CANCEL_TRANSACTION.
CSet the LOCK_TIMEOUT to FALSE in the stored procedure.
DSet the TRANSACTION_ABORT_ON_ERROR to TRUE in the stored procedure.
A Data Engineer needs to check the status of a pipe named my_pipe. The pipe is located in a database named test and a schema named Extract (case-sensitive).
CSELECT * FROM SYSTEM$PIPE_STATUS('test."Extract".my_pipe');
DSELECT * FROM SYSTEM$PIPE_STATUS("test.'extract'.my_pipe");
A Data Engineer has found that numerous tables in the company database include sensitive information about products that are not yet in production. The information is distributed across multiple tables and across different columns in each table. The Engineer is prioritizing protection of the data in the packaging table, with access limited to users in the researcher and marketing roles. All tables containing sensitive data must be identified to improve data-governance management.
How can these requirements be satisfied with the least operational overhead?
A
B
C
D
A secure function returns data received through an inbound share.
What occurs if a Data Engineer attempts to grant USAGE privileges on this function to an outbound share?
AAn error will be returned because the Engineer cannot share data that has already been shared.
BAn error will be returned because only views and secure stored procedures can be shared.
CAn error will be returned because only secure functions can be shared with inbound shares.
DThe Engineer will be able to share the secure function with other accounts.
A tag called DEPARTMENT has two values: MARKETING and FINANCE.
Which command adds ENGINEERING as a third value to the tag?
AALTER TAG DEPARTMENT ADD ALLOWED_VALUES 'ENGINEERING';
BALTER TAG DEPARTMENT MODIFY ALLOWED_VALUES 'ENGINEERING';
CALTER TAG DEPARTMENT SET TAG DEPARTMENT = 'ENGINEERING';
DALTER TAG DEPARTMENT DROP ALLOWED VALUES 'MARKETING', 'FINANCE' ADD ALLOWED VALUES 'MARKETING', 'FINANCE', 'ENGINEERING';
A REST API on an on-premises network must be used to ingest data into Snowflake. Due to network restrictions, Snowflake cannot access the data. The data owners propose pushing data to Azure Blob storage every five minutes and running a COPY INTO command, but the Data Engineer is worried about cost. Data transformations will be performed with views after the data is ingested.
Data consumers do not need real-time data, but they expect the data to refresh about every 5 minutes.
Which data-ingestion approach is MOST cost-effective?
AUse a COPY INTO command to move the data from Blob storage to Snowflake.
BUse Snowpipe Streaming to ingest the on-premises data using a Kafka stream.
CUse Snowpipe Streaming and call the Snowpipe API to insert the data into the Snowflake tables.
DUse Blob storage to store the data, then use Amazon Simple Queue Service (SQS) to trigger Snowpipe and initiate the data loading into Snowflake.
A large, 200-column table holds two years of historical data. Queries against it filter on a single day. The following is the Query Profile:
When run on a 2XL virtual warehouse, this query required more than one hour to finish. What will improve query performance the MOST?
AIncrease the size of the virtual warehouse.
BIncrease the number of clusters in the virtual warehouse.
CImplement the search optimization service on the table.
DAdd a date column as a cluster key on the table.
A Data Engineer creates the following masking policy:
The policy must be assigned to the full_name column in the customer table:
Which query applies the masking policy to the full_name column?
AALTER TABLE customer MODIFY COLUMN full_nameSET MASKING POLICY name policy;
A company created data pipelines with dynamic tables in Snowflake. Recently, certain dynamic table refreshes have taken longer than expected, delaying data availability for downstream reporting and increasing costs.
How should inefficient dynamic table refreshes and resource utilization be monitored?
Choose two
AIncrease the refresh table frequency to keep the data fresh and improve reporting accuracy.
BUse Snowsight or the DYNAMIC_TABLE_REFRESH_HISTORY function to monitor the refresh history of each dynamic table.
CSet the dynamic tables to full refresh mode to simplify the monitoring process and ensure downstream data availability on a consistent schedule.
DMonitor the QUERY_HISTORY view to analyze the performance of the virtual warehouse used to refresh the dynamic tables, to ensure that the warehouse is sized appropriately.
ESchedule this query to analyze the dynamic table performance:SELECT *FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(scheduled_time_range_3tart => DATEADD(HOUR, -1, CURRENT_TTMESTAMP())));
Which file-format option should be used to escape the \ character when unloading data from a table to a stage if FIELD_DELIMITER = ','?
AESCAPE_UNENCLOSED_FIELD=NONE
BESCAPE_UNENCLOSED_FIELD='\'
CESCAPE_UNENCLOSED_FIELD=''
DESCAPE UNENCLOSED FIELD=','
A Data Engineer created table T1 with DATA_RETENTION_TIME_IN_DAYS set to 7. A default stream, S1, exists on table T1.
The MAX_DATA_EXTENSION_TIME_IN_DAYS parameter is set to 10 for table T1.
Based on these parameters, at a minimum, how often must the contents of stream S1 be consumed to keep the stream from becoming stale?
AEvery 3 days
BEvery 7 days
CEvery 10 days
DEvery 30 days
Which Snowflake Continuous Data Protection (CDP) feature consumes compute credits when used?
ACreating zero-copy clones
BEnabling Multi-Factor Authentication (MFA)
CUsing Role-Based Access Control (RBAC)
DRetrieval of data from Fail-safe
Database XYZ has its data_retention_time_in_days parameter set to 7 days, while table XYZ.public.ABC has data_retention_time_in_days set to 10 days.
A Developer accidentally dropped the database containing this only table 8 days ago and has just discovered the error.
How can the table be recovered?
Aundrop database xyz;
Bcreate table abc_restore as select * from xyz.public.abc at (offset => -606024*8);
Ccreate table abc_restore clone xyz.public.abc at (offset => -3600248);
DCreate a Snowflake Support case to restore the database and table from Fail-safe.
For the cron expression 0 1 * * * America/Los_Angeles, how does the task behave when Daylight Saving Time changes to Standard Time and the clock moves back by one hour?
AThe task will run once.
BThe task will run twice.
CThe task will not run.
DThe task will fail with an error.
Which command retrieves results for all objects of the row access policy db1.policies.objectslist at the database level?
ASELECT * FROM TABLE( db1.ACCOUNT_USAGE.POLICY_REFERENCES(POLICY_NAME=>'db1.policies.objectslist' ) );
BSELECT * FROM TABLE( db1.INFORMATION_SCHEMA.POLICY_REFERENCES(POLICY_NAME=>'db1.policies.objectslist' ) );
CSELECT * FROM TABLE( db1.ACCOUNT_USAGE.ROW_ACCESS_POLICIES(POLICY_NAME=>'db1.policies.objectslist' ) );









Community Discussion