SnowPro Advanced Architect Practice Exam — Free Online Mock Test
QuestionQ1
Secure Data Sharing and Consumption
Save question
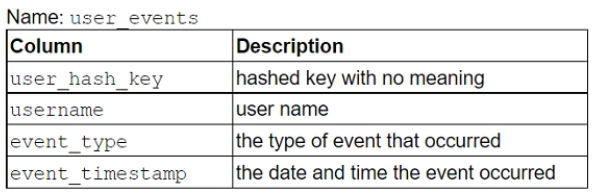
The following table is present in the production database:
A regulatory requirement requires the company to mask the username for events older than six months, determined from the current date when the data is queried.
How can this requirement be met without duplicating the event data, while ensuring it is applied when creating views from the table or cloning the table?
AUse a masking policy on the username column using an entitlement table with valid dates.
BUse a row level policy on the user_events table using an entitlement table with valid dates.
CUse a masking policy on the username column with event_timestamp as a conditional column.
DUse a secure view on the user_events table using a case statement on the username column.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Secure Data Sharing and Consumption
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Performance, Cost, and Resource Optimization
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ4
Performance, Cost, and Resource Optimization
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ5
Data Storage and Processing
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
Architecture OverviewData Ingestion and Data PreparationData Storage and ProcessingSecure Data Sharing and ConsumptionPerformance, Cost, and Resource Optimization
How are Snowflake databases created from shares different from standard databases that were not created from shares?
Choose three
AShared databases are read-only.
BShared databases must be refreshed in order for new data to be visible.
CShared databases cannot be cloned.
DShared databases are not supported by Time Travel.
EShared databases will have the PUBLIC or INFORMATION_SCHEMA schemas without explicitly granting these schemas to the share.
FShared databases can also be created as transient databases.
An Architect is designing a Snowflake architecture that must execute Data Analyst reports very quickly. To optimize costs, the virtual warehouse is configured to auto-suspend after 2 minutes of idle time. The Architect runs the queries once in the morning after the data refresh, hoping that all subsequent queries will use the warehouse cache. However, later in the day, subsequent queries run slowly.
Why is this happening?
AThe warehouse is not large enough.
BThe warehouse was not configured as a multi-cluster warehouse.
CThe warehouse was not created with the use_cache = true parameter enabled.
DWhen the warehouse was suspended, the cache was dropped.
An Architect is investigating a long-running statement and must identify the transactions that are blocked and the queries blocking them.
Which views should be used for troubleshooting?
Choose two
AQUERY_HISTORY
BOBJECT_DEPENDENCIES
CDATA_TRANSFER_HISTORY
DLOCK_WAIT_HISTORY
EACCESS HISTORY
An account is using the default setting for every parameter. The MERGE command updates or deletes target rows that join to multiple source rows.
What will be the outcome of the MERGE statement?
AAn error will be returned that includes values from one of the target rows that caused the error.
BThe merge will complete successfully, and the results of the merge will be nondeterministic.
CThe merge will be performed based on the first match of the multiple source rows with the target row.
DThe merge will be performed based on the last match of the multiple source rows with the target row.
QuestionQ6
Secure Data Sharing and Consumption
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ7
Secure Data Sharing and Consumption
QuestionQ8
Data Ingestion and Data Preparation
QuestionQ9
Performance, Cost, and Resource Optimization
QuestionQ10
Performance, Cost, and Resource Optimization
QuestionQ11
Data Storage and Processing
QuestionQ12
Secure Data Sharing and Consumption
QuestionQ13
Performance, Cost, and Resource Optimization
QuestionQ14
Data Storage and Processing
QuestionQ15
Secure Data Sharing and Consumption
QuestionQ16
Secure Data Sharing and Consumption
QuestionQ17
Data Ingestion and Data Preparation
QuestionQ18
Data Ingestion and Data Preparation
QuestionQ19
Data Ingestion and Data Preparation
QuestionQ20
Secure Data Sharing and Consumption
QuestionQ21
Secure Data Sharing and Consumption
QuestionQ22
Performance, Cost, and Resource Optimization
QuestionQ24
Secure Data Sharing and Consumption
QuestionQ25
Data Storage and Processing
QuestionQ26
Performance, Cost, and Resource Optimization
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
A data share exists between a data provider account and a data consumer account. Five tables from the provider account are shared with the consumer account. The consumer role has been granted the IMPORTED PRIVILEGES privilege.
What occurs in the consumer account when a new table (table_6) is added to the provider schema?
AThe consumer role will automatically see the new table and no additional grants are needed.
BThe consumer role will see the table only after this grant is given on the consumer side:grant imported privileges on database PSHARE_EDW_4TEST_DB to DEV_ROLE;
CThe consumer role will see the table only after this grant is given on the provider side:use role accountadmin;Grant select on table EDW.ACCOUNTING.Table_6 to share PSHARE_EDW_4TEST;
DThe consumer role will see the table only after this grant is given on the provider side:use role accountadmin;grant usage on database EDW to share PSHARE_EDW_4TEST ;grant usage on schema EDW.ACCOUNTING to share PSHARE_EDW_4TEST ;Grant select on table EDW.ACCOUNTING.Table_6 to database PSHARE_EDW_4TEST_DB
A company has an AWS account in the us-east-1 Region and must share data with vendors that also have Snowflake accounts on AWS in that same Region. The company maintains non-sensitive data in its database for every vendor. The company does not need to retain or monitor telemetry data from consumer accounts.
Which data-collaboration method will enable the company to monetize the data shares and track data usage over time with the least operational overhead?
AA direct share with access granted to all vendor accounts
BA data share associated with a paid listing with access granted to all vendor accounts
CAn approved application on a paid listing with access granted to all vendor accounts
DA reader account with users created for all vendors
Why does the conditional multi-table INSERT option support the Data Vault data model?
AData can be inserted in parallel to hubs and satellites using surrogate keys.
BData can be inserted in parallel to dimensions and facts using surrogate keys.
CData can be inserted in sequence to hubs and satellites using surrogate keys.
DData can be inserted in sequence to dimensions and facts using surrogate keys.
An Architect has configured Cross-Cloud Auto-Fulfillment for a data listing. After the initial auto-fulfillment completed for a customer in a remote region, a data-refresh synchronization must be configured based on a weekly update to the listing data.
Based on this workload, which data refresh configuration requires the LEAST operational overhead?
ATrigger refreshes
BInterval refreshes
CFull refreshes
DAuto refreshes
What is an important consideration when configuring the search optimization service for a table?
ASearch optimization service works best with a column that has a minimum of 100 K distinct values.
BSearch optimization service can significantly improve query performance on partitioned external tables.
CSearch optimization service can help to optimize storage usage by compressing the data into a GZIP format.
DThe table must be clustered with a key having multiple columns for effective search optimization.
A company has a table named Data that contains corrupted data. The company wants to recover the data as it existed 5 minutes ago by using cloning and Time Travel.
Which command will accomplish this?
ACREATE CLONE TABLE Recover_Data FROM Data AT(OFFSET => -60*5);
BCREATE CLONE Recover_Data FROM Data AT(OFFSET => -60*5);
CCREATE TABLE Recover_Data CLONE Data AT(OFFSET => -60*5);
DCREATE TABLE Recover Data CLONE Data AT(TIME => -60*5);
A company that is new to Snowflake can connect to its account with SnowSQL, but it receives the following error message in the connection logs:
SEVERE: WARNING!!! Using fail-open to connect. Driver is connecting to an HTTPS endpoint without OCSP based Certificate Revocation checking as it could not obtain a valid OCSP Response to use from the CA OCSP responder.
What does this message indicate?
Choose two
AThe SnowSQL ocsp_fail_open parameter is set to use the default value in the connection.
BPrivate Link is not enabled in the account.
CThe DNS team did not allow port 443 in the firewall.
DThe DNS team did not allow port 80 in the firewall.
EThe client IP is not on the allow list.
Which performance-optimization techniques can affect storage costs?
Choose two
ARewriting a query
BUsing the search optimization service
CCreating a multi-cluster virtual warehouse
DEnabling Automatic Clustering
EIncreasing the MIN_CLUSTER_COUNT in a multi-cluster virtual warehouse
An Architect runs the following statements in sequence:
create table emp(id integer);
insert into emp values (1),(2);
create temporary table emp(id integer);
insert into emp values (1);
The Architect then runs these statements:
select count(*) from emp;
drop table emp;
select count(*) from emp;
What is the result?
ACOUNT ()2COUNT ()1
BCOUNT ()1COUNT ()2
CCOUNT ()2COUNT ()2
DThe final query will result in an error.
A healthcare company requires a data-sharing solution that enables collaboration with an insurance company to analyze patient treatment outcomes and improve service offerings. The solution must meet these requirements:
Both companies can provide and consume data.
Sensitive data is protected.
A data provider can define how the data consumer interacts with the data by using query templates.
Which solution meets these requirements with the LEAST operational overhead?
ADirect shares
BData Clean Rooms
CListings
DData Exchange
The IT Security team has identified an ongoing credential-stuffing attack across many of the organization’s systems.
What is the BEST method to find recent and ongoing login attempts to Snowflake?
ACall the LOGIN_HISTORY Information Schema table function.
BQuery the LOGIN_HISTORY view in the ACCOUNT_USAGE schema in the SNOWFLAKE database.
CView the History tab in the Snowflake UI and set up a filter for SQL text that contains the text "LOGIN".
DView the Users section in the Account tab in the Snowflake UI and review the last login column.
Files arrive in an external stage every 10 seconds from a proprietary system. The files range in size from 500 K to 3 MB. The data must be available to dashboards as soon as it arrives.
How can a Snowflake Architect satisfy this requirement with the LEAST amount of coding?
Choose two
AUse Snowpipe with auto-ingest.
BUse a COPY command with a task.
CUse a materialized view on an external table.
DUse the COPY INTO command.
EUse a combination of a task and a stream.
Consider the following COPY command, which loads CSV-formatted data into a Snowflake table from an internal stage by using a data-transformation query.
Assuming the syntax is correct, what causes this error?
AThe VALIDATION_MODE parameter supports COPY statements that load data from external stages only.
BThe VALIDATION_MODE parameter does not support COPY statements with CSV file formats.
CThe VALIDATION_MODE parameter does not support COPY statements that transform data during a load.
DThe value return_all_errors of the option VALIDATION_MODE is causing a compilation error.
A company receives transaction data in CSV format that is automatically delivered to an Amazon S3 bucket. Snowpipe is configured with event notifications to ingest files into Snowflake when they arrive in the S3 bucket. There are concerns that the S3 bucket is becoming too large because of already processed files and that some files might have been loaded more than once.
Which actions address these concerns?
Choose two
ARemove staged files that are no longer needed by periodically executing the REMOVE command.
BConfigure data lifecycle management features provided by the cloud storage service provider.
CEnable Snowpipe’s file name deduplication feature to prevent files from being reprocessed.
DMove loaded files using the COPY INTO command with a PATTERN filter to avoid reprocessing.
EConfigure the Snowpipe AUTO_INGEST parameter to = TRUE to automatically delete loaded files from the S3 bucket.
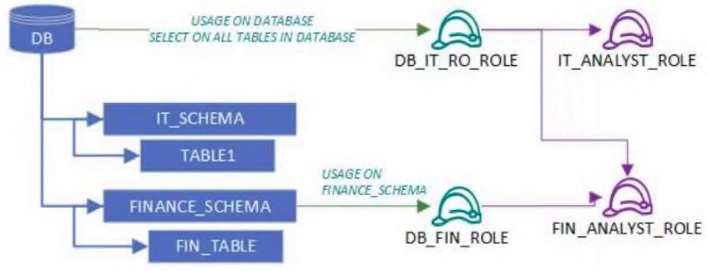
User1 and User2 are new users, each granted a different functional role. User1 received IT_ANALYST_ROLE, and User2 received FIN_ANALYST_ROLE.
Review the following security design:
Which tables can each role read?
AUser1 will be the only user to read the tables from both schemas, since the DB_IT_RO_ROLE role has SELECT privileges on all the database tables.
BUser1 will be able to read the tables from both schemas, while User2 will be able to read only the FINANCE_SCHEMA tables.
CUser2 will be able to read the tables from the FINANCE_SCHEMA, while User1 will be unable to read any table.
DUser2 will be able to read the tables from both schemas, while User1 will be able to read the tables only in IT_SCHEMA.
A company uses Snowflake to store and analyze its customer data. The company must meet a strict regulatory requirement to protect Personally Identifiable Information (PII).
What should an Architect do to satisfy this requirement?
AUse row-level security to mask PII data.
BUse tag-based masking policies for columns that contain PII data.
CCreate secure views for the PII data and grant access to the views as needed.
DCreate separate tables for columns containing PII and those that do not; grant access as needed
Assuming every Snowflake account uses Enterprise edition or higher, in which development and testing scenarios is data copying required, making zero-copy cloning unsuitable?
Choose two
ADevelopers create their own datasets to work against transformed versions of the live data.
BProduction and development run in different databases in the same account, and Developers need to see production-like data but with specific columns masked.
CData is in a production Snowflake account that needs to be provided to Developers in a separate development/testing Snowflake account in the same cloud region.
DDevelopers create their own copies of a standard test database previously created for them in the development account, for their initial development and unit testing.
EThe release process requires pre-production testing of changes with data of production scale and complexity. For security reasons, pre-production also runs in the production account.
Can a Snowflake data provider account using the Business Critical edition share data with a data consumer account using the Enterprise edition?
AA Business Critical account cannot be a data sharing provider to an Enterprise consumer. Any consumer accounts must also be Business Critical.
BIf a user in the provider account with role authority to CREATE or ALTER SHARE adds an Enterprise account as a consumer, it can import the share.
CIf a user in the provider account with a share owning role sets SHARE_RESTRICTIONS to False when adding an Enterprise consumer account, it can import the share.
DIf a user in the provider account with a share owning role which also has OVERRIDE SHARE RESTRICTIONS privilege SHARE_RESTRICTIONS set to False when adding an Enterprise consumer account, it can import the share.
An Architect wants to retain quarter-end financial results for the past six years.
Which Snowflake feature can the Architect use to achieve this?
ASearch optimization service
BMaterialized view
CTime Travel
DZero-copy cloning
ESecure views
An Architect has been asked to address a performance issue involving a transformation in a data pipeline. The issue started when the transformation logic for the SALES table was modified to add additional dimensions to aggregations (DEPARTMENT_ID, REGION_ID, DEALER_ID).
New sales regions have been added, and the data volume has doubled. The table now processes 20 million records, whereas it previously processed 10 million. Runtime has risen from 5 minutes to more than 20 minutes. Warehouse spilling has been identified as a possible cause.
How can performance be improved?
Choose two
AUse the search optimization service.
BIncrease the size of the virtual warehouse.
CSplit the data processing into several steps.
DDecrease the number of parallel queries running in the warehouse.
EIncrease the value of the STATEMENT_TIMEOUT_IN_SECONDS parameter.

Community Discussion