Why would an Enterprise Architect use a single enterprise-wide canonical data model (CDM) when designing an integration solution using Anypoint Platform?
ATo reduce dependencies when integrating multiple systems that use different data formats
BTo remove the need to perform data transformation when processing message payloads in Mule applications
CTo leverage a data abstraction layer that shields existing Mule applications from non-backward compatible changes to the model’s data structure
DTo automate AI-enabled API implementation generation based on normalized backend databases from separate vendors
0
Question 2
ABOUT THE EXAM
0
Question 3
ABOUT THE EXAM
0
Question 4
ABOUT THE EXAM
0
Question 5
ABOUT THE EXAM
0
That's the end of the Preview
This exam has 60 community-verified practice questions. Create a free account to access all questions, comments, and explanations.
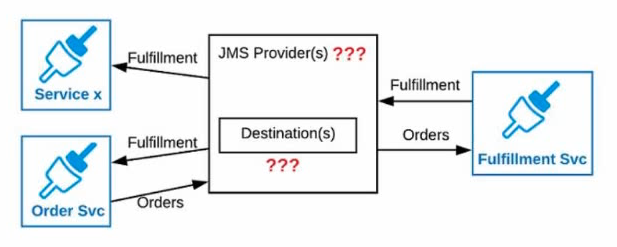
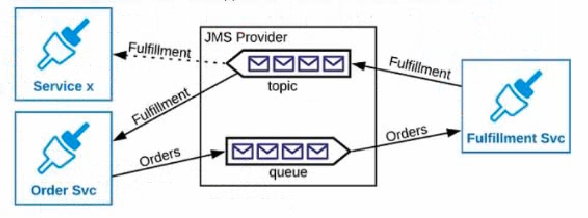
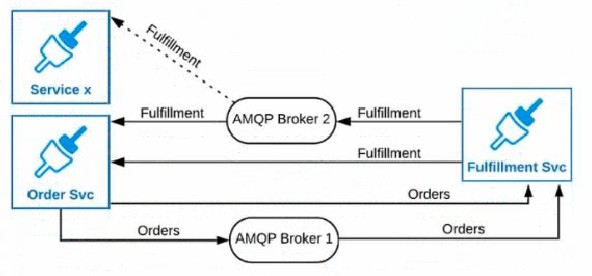
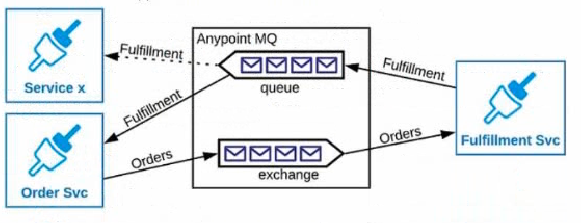
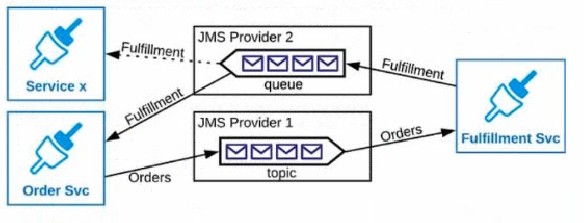
Refer to the exhibits.
An Order microservice and a Fulfillment microservice are being designed to communicate with their clients through message-based integration (and NOT through API invocations).
The Order microservice publishes an Order message (a kind of command message) containing the details of an order to be filled. The intent is that Order messages are only consumed by one Mule application: the Fulfillment microservice.
The Fulfillment microservice consumes Order messages, fills the orders described therein, and then publishes a Fulfillment message (a kind of event message). Each Fulfillment message can be consumed by any interested Mule application, and the Order microservice is one such Mule application.
What is the recommended choice of message broker(s) and message destination(s) in this scenario?
A
B
C
D
An organization is struggling with frequent version upgrades and external plugin project dependencies. The team wants to minimize the impact on applications by creating best practices that will define a set of default dependencies across all new and in-progress projects.
How can these best practices be achieved with the applications having the least amount of responsibility?
ACreate a Mule plugin project with all dependencies and add it as a dependency in each application’s pom.xml file
BCreate a Mule domain project with all the dependencies defined in its pom.xml file and add each application to the domain project
CAdd all the dependencies in each application’s pom.xml file
DCreate a parent POM with all the required dependencies and reference it in each application’s pom.xml file
Following MuleSoft’s recommended best practices for API governance and API policies, a project team has used RAML specifications to document and publish functional requirements and detailed design definitions of its APIs. These API specifications have been used by various stakeholders to implement APIs.
Later, the project team requires all API specifications to be augmented with an additional non-functional requirement (NFR) to protect the backend services from a high rate of requests, according to defined service-level agreements (SLAs). The NFR’s SLAs are based on a new tiered subscription level “Gold”, “Silver”, or “Platinum” that must be tied to a new parameter that is being added to the Accounts object in their enterprise data model.
Following MuleSoft’s recommended best practices, how should the project team now convey the necessary non-functional requirement to stakeholders?
ACreate a shared RAML fragment required to implement the NFR, list each API implementation endpoint in the RAML fragment, and publish the RAML fragment to Exchange
BCreate and deploy API proxies in API Manager for the NFR, change the baseUrl in each API specification to the corresponding API proxy implementation endpoint, and publish each modified API specification to Exchange
CUpdate each API specification with comments about the NFR’s SLAs and publish each modified API specification to Exchange
DUpdate each API specification with a shared RAML fragment required to implement the NFR and publish the RAML fragment and each modified API specification to Exchange
A Mule application is required to periodically process a large data set from a back-end database to Salesforce CRM using a Batch Job scope configured properly to process the high rate of records. The Mule applications is deployed to two CloudHub 1.0 workers with the persistent VM queues option disabled (unchecked).
What is the consequence if a worder that is processing records from a Batch Job scope crashes during records processing?
AAll the remaining records will be processed by a new replacement worker, resulting in “exactly once” processing of every record
BRemaining records will be lost, resulting in unprocessed records
CAbout half the remaining records will be processed by the second worker and the rest will be lost, resulting in some unprocessed records
DThe entire batch job will be processed from scratch by the second worker, resulting in some duplicate processing
Question 6
ABOUT THE EXAM
0
Question 7
ABOUT THE EXAM
Question 8
ABOUT THE EXAM
Question 9
ABOUT THE EXAM
Question 10
ABOUT THE EXAM
Question 11
ABOUT THE EXAM
Question 12
ABOUT THE EXAM
Question 13
ABOUT THE EXAM
Question 14
ABOUT THE EXAM
Question 15
ABOUT THE EXAM
Question 16
ABOUT THE EXAM
Question 17
ABOUT THE EXAM
Question 18
ABOUT THE EXAM
Question 19
ABOUT THE EXAM
Question 20
ABOUT THE EXAM
Question 21
ABOUT THE EXAM
Question 22
ABOUT THE EXAM
Question 23
ABOUT THE EXAM
Question 24
ABOUT THE EXAM
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ad
Want a break from the ads?
Become a Supporter and enjoy a completely ad-free experience, plus unlock Learn Mode, Exam Mode, AstroTutor AI, and more.
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
A Mule solution implements an Experience API and System API as Mule applications that process messages in this order:
Experience API receives a request Anypoint MQ message (REQU) with a payload containing a variable-length list of request objects.
The Experience API uses a For Each scope to split the list into individual objects and sends each object a REQU_OBJECT message to an
Anypoint MQ queue named REQUEST.
The Sytem API listens on the REQUEST queue, processes each message independently of all other messages, and sends a response message to a response queue named RESPONSE_OBJECT.
The System API processing times can vary and are occasionally fairly long.
The Experience API listens on the RESPONSE_OBJECT queue and receives, transforms, and accumulates each response.
After receiving all the responses corresponding to the original REQU message, the Experience API creates and publishes a response Anypoint MQ message (RESP) to an Anypoint MQ queue named RESPONSE with a payload containing the list of responses returned by the System API, organized in the same order as the request objects originally sent in the REQU message.
Assume successful response messages are returned by Experience API to the RESPONSE queue for all REQU messages.
What is required so the Experience API can ensure the length and order of the list of objects in RESP and REQU match, while at the same time maximizing message throughput?
AAfter the For Each scope, add a second For Each scope configured with a persistent object store to collect response messages in the order in which they arrive, and then send the RESP message using this list of responses.
BPerform all communication involving the System API synchronously from within the For Each scope so that responses in RESPONSE_OBJECT are in the exact same order as request objects in the RESP message.Within the For Each scope, use an Async scope configured with a persistent object store.
CUse a persistent object store to keep track of the list length and all object indexes in the REQU message, both in the For Each scope and in all communication involving the System API.Set the maxConcurrency parameter for the receiving flow in the Experience API to a value greater than 1.
DUse a Scatter-Gather within the For Each scope to ensure response message order.Configure the Scatter-Gather with a persistent object store.
An organization is the process of building automated deployments using a CI/CD process. As a part of automated deployments, it wants to apply policies to API instances.
What tool can the organization use to promote and deploy API Manager policies?
AMule Maven plugin
BMUint Maven plugin
CAnypoint CLI
DRuntime Manager agent
A project team is working on an API implementation using an API RAML specification as a starting point. The team has updated the RAML specification to include new operations, and has published a new version to Exchange. Meanwhile, another team is working on an API client Mule application to consume the same API implementation.
During this development, what must be performed by the Mule application team to take advantage of the newly added operations?
ACopy the API implementation’s updated APIkit component into the API client
BUpdate the API connector in the API implementation and publish to Exchange
CUpdate the REST connector from Exchange in the API client application
DScaffold the API client application with APIkit using the new RAML specification
An architect is designing a Mule application to meet the following two requirements:
The application must process files asynchronously and reliably from an FTPS server to a back-end database using VM intermediary queues for load-balancing Mule events.
The application must process a medium rate of records from a source to a target system using a Batch Job scope.
To make the Mule application more reliable, the Mule application will be deployed to two CloudHub 1.0 workers.
Following MuleSoft-recommended best practices, how should the Mule application deployment typically be configured in Runtime Manger to best support the performance and reliability goals of both the Batch Job scope and the file processing VM queues?
AIn the Runtime Manager Properties tab, disable persistent VM queues for Batch Job scopes
BCheck the Non-persistent VM queues checkbox in the application deployment configuration
CCheck the Persistent VM queues checkbox in the application deployment configuration
DIn the Runtime Manager Properties tab, enable persistent VM queues for the FTPS connector
An organization is successfully using API-led connectivity. However, as the application network grows, all the manually performed tasks to publish, share and discover, register, apply policies to, and deploy an API are becoming repetitive, which is driving the organization to automate this process using efficient CI/CD pipelines.
Considering Anypoint Platform’s capabilities, how should the organization automate its API lifecycle?
AUse Runtime Manager REST APIs for API management and Maven for API deployment
BUse Anypoint CLI or Anypoint Platform REST APIs with a scripting language such as Groovy
CUse Maven with a custom configuration required for the API lifecycle
DUse Exchange REST APIs for API management and Maven for API deployment
An organization has strict unit test requirements that mandate every Mule application must have an MUnit test suite with a test case defined for each flow and a minimum test coverage of 80 percent.
A developer is building an MUnit test suite for a newly developed Mule application that sends API requests to an external REST API.
What is an effective approach for successfully executing the MUnit tests of this Mule application while still achieving the required test coverage for the MUnit tests?
AMock the REST API invocations in the MUnit tests, and then forward mocked requests to the external REST API
BInvoke the external endpoint of the REST API from the Mule flows
CMock the REST API invocations in the MUnit tests, and then return a mock response for those invocations
DCreate a mocking service flow to simulate standard responses from the REST API, and then configure the Mule flows to call the mocking service flow
A cluster with two customer-hosted Mule runtimes is hosting an application that has a flow with a JMS listener configured to subscribe to messages from a topic destination.
How should the JMS listener’s primaryNodeOnly parameter and subscription parameter be configured so the JMS listener can receive messages in all the nodes of the cluster but only process each message once?
AUse the parameter primaryNodeOnly = “false” on the JMS listener with a shared subscription
BUse the parameter primaryNodeOnly = “false” on the JMS listener with a non-shared subscription
CUse the parameter primaryNodeOnly = “true” on the JMS listener with a non-shared subscription
DUse the parameter primaryNodeOnly = “true” on the JMS listener with a shared subscription
A retail company is implementing a MuleSoft API to get inventory details from two vendors by invoking each vendor’s online applications. Due to network issues, the invocations to the vendor applications are timing out intermittently, but the requests are successful after re-invoking each vendor application.
What is the most performant way of implementing the API to invoke each vendor application and to retry invocations that generate timeout errors?
AUse a Round-Robin scope to invoke each vendor application on a separate route.Use a Try-Catch scope in each route to retry request that raise timeout errors.
BUse a Scatter-Gather scope to invoke each vendor application on separate route.Use an Until-Successful scope in each route to retry requests that raise timeout errors.
CUse a Choice scope to invoke each vendor application on a separate route.Place the Choice scope to invoke inside an Until-Successful scope to retry requests that raise timeout errors.
DUse a For-Each scope to invoke the two vendor applications in series, one after the other.Place the For-Each scope inside a Unit-Successful scope to retry requests that raise timeout errors.
A stock trading company handles millions of trades a day and requires excellent performance and reliability within its stock trading system. The company operates a number of event-driven APIs implemented as Mule applications that are hosted on various customer-hosted Mule clusters and needs to enable message exchanges between the APIs within their internal network using shared message queues.
What is an effective way to meet the cross-cluster messaging requirements of its event-driven APIs?
AeXtended Architecture (XA) transactions and XA connected components with manual acknowledgements
BPersistent VM queues with automatic acknowledgements
CJMS transactions with automatic acknowledgements
DNon-transactional JMS operations with a reliability pattern and manual acknowledgements
A Mule application uses an HTTP Request operation to invoke an external API. The external API follows the HTTP specification for proper status code usage.
What is a possible cause when a 3xx status code is returned to the HTTP Request operation from the external API?
AThe request was not received by the external API
BThe request was received and processed by the external API
CThe request was received and rejected by the external API
DThe request was redirected to a different URL by the external API
A Mule application is synchronizing customer data between two different database systems.
What is a main benefit of using eXtended Architecture (XA) transactions rather than local transactions to synchronize these two different database systems?
AAn XA transaction synchronizes the database systems with the least amount of Mule configuration or coding
BAn XA transaction handles the largest number of requests in the shortest time
CAn XA transaction automatically rolls back operations against both database systems if any operation fails
DAn XA transaction writes to both database systems quickly and simultaneously
An external API frequently invokes an Employees system API to fetch employee data from a MySQL database. The architect must design a caching strategy to query the database only when there is an update to the Employees table or else return a cached response in order to minimize the number of redundant transactions being handled by the database.
What must the architect do to achieve the caching objective?
AUse a Scheduler with a fixed frequency set to every hour to trigger an invalidate cache flow.Use an object-store-caching-strategy and the default expiration interval.
BUse a Scheduler with a fixed frequency set to every hour, triggering an invalidate cache flow.Use an object-store-caching-strategy and set the expiration interval to 1 hour.
CUse an On Table Row operation configured with the Employees table and call invalidate cache.Use an object-store-caching-strategy and the default expiration interval.
DUse an On Table Row operation configured with the Employees table, call invalidate cache, and hardcode the new Employees data to cache.Use an object-store-caching-strategy and set the expiration interval to 1 hour.
A corporation has deployed Mule applications to different customer-hosted Mule runtimes. Mule applications deployed to these Mule runtimes are managed by Anypoint Platform.
What needs to be installed or configured (if anything) to monitor these Mule applications from Anypoint Monitoring, and how is monitoring data from each Mule application sent to Anypoint Monitoring?
AInstall an Anypoint Monitoring agent on each Mule runtime.Each Anypoint Monitoring agent sends monitoring data from the Mule applications running in its Mule runtime to Anypoint Monitoring.
BLeave the out-of-the-box Anypoint Monitoring agent unchanged in its default Mule runtime installation.Each Anypoint Monitoring agent sends monitoring data from the Mule applications running in its Mule runtime to Runtime Manager, then Runtime Manager sends monitoring data to Anypoint Monitoring.
CInstall a Runtime Manager agent on each Mule runtime.Each Runtime Manager agent sends monitoring data from the Mule applications running in its Mule runtime to Runtime Manager, then Runtime Manager sends monitoring data to Anypoint Monitoring.
DEnable monitoring of individual Mule applications from the Runtime Manager application settings.Runtime Manger sends monitoring data to Anypoint Monitoring for each deployed Mule application.
When a Mule application using VM queues is deployed to a customer-hosted cluster or multiple CloudHub v1.0 workers/replicas, how are messages consumed across the nodes?
ARound-robin, within an XA transaction
BSequentially, from a dedicated Anypoint MQ queue
CSequentially, only from the primary node
DIn a non-deterministic way
An organization has built a large monolithic application over the years and is currently looking to transition to a microservices architecture. During this transition phase, it has built some System APIs as Mule applications that provide access to different pieces of functionality of the monolithic application. The System APIs are deployed to Mule runtimes in a customer-hosted EC2 instance in AWS.
The System API communicate directly with one database used by the monolithic application. Currently, a Database connector and configuration for that connector must be built into every project. There is a plan to partition this database into various smaller data stores in the future.
What is the MuleSoft-recommended best practice to share the connector and configuration information among the APIs?
ACreate an API proxy for each System API and share the Database connector configuration with all the API proxies via an automated policy
BBuild another System API that connects to the database, and refactor all the other APIs to make requests through the new System API to access the database
CBuild a Mule domain project, add the Database connector and configuration to it, and reference this one domain project from each System API
DBuild a separate Mule domain project for each API, and configure each of them to use a file on a shared file store to load the configuration information dynamically
An organization is designing multiple Mule applications to run on CloudHub in a single Anypoint VPC and that must share data using a common persistent Anypoint Object Store v2 (OSv2).
What design gives these Mule applications access to the same Object Store instance?
AAn Anypoint MQ connector configured to directly access the persistent Object Store
BThe Object Store v2 can be shared across CloudHub applications with a configured OS v2 connector
CThe Object Store v2 REST API configured to access the persistent Object Store
DA VM connector configured to directly access the persistence queue of the persistent Object Store
A bank is implementing a REST API in a Mule application to receive an array of accounts from an online banking platform user interface (UI), retrieve account balances for those accounts from a backend Finance system, and then return the account balances so they can be displayed in the online banking platform UI. As part of the processing, the MuleSoft API also needs to insert the retrieved account data into an Audit Database for auditing purposes. The auditing process should not add latency to the account balance retrieval response back to the online banking platform UI.
The retrieveBalances flow in the Mule application is designed to use an operation in a connector to the Finance system (the Finance operation) that can only look up one account record at a time, and an operation from a different connector to the Audit system (the Audit operation) that can only insert one account record at a time.
To best meet the performance-related requirements, what scope or scopes should be used and how should they be used to incorporate the Finance operation and Audit operation into the retrieveBalances flow?
AWrap both connector operations in a For-Each scope.
BWrap the Finance operation in an Until-Successful scope.Wrap the Audit operation in a Try-Catch scope.
CWrap the Finance operation in a Parallel For-Each scope.Wrap the Audit operation in an Async scope.
DWrap both connector operations in an Async scope.
A payment processing company has implemented a Payment Processing API Mule application to process credit card and debit card transactions. Because the Payment Processing API handles highly sensitive information, the payment processing company requires that data must be encrypted both in-transit and at-rest.
To meet these security requirements, consumers of the Payment Processing API must create request message payloads in a JSON format specified by the API, and he message payload values must be encrypted.
How can the Payment Processing API validate requests received from API consumers?
AA Transport Layer Security (TLS) – Inbound policy can be applied in API Manager to decrypt the message payload and the Mule application implementation can then use the JSON Validation module to validate the JSON data
BThe Mule application implementation can use the APIkit module to decrypt and then validate the JSON data
CThe Mule application implementation can use the Validation module to decrypt and then validate the JSON data
DThe Mule application implementation can use DataWeave to decrypt the message payload and then use the JSON Scheme Validation module to validate the JSON data
A company is modernizing its legacy systems to accelerate access to applications and data while supporting the adoption of new technologies. The key to achieving this business goal is unlocking the company’s systems and data, including a set of existing services hosted on-premises that can be accessed by authorized external clients. The IT staff is mainly experienced only with supporting its legacy systems.
Considering the current aggressive backlog and the project delivery requirements, the company wants to take a strategic approach in the first phase of its transformation projects by quickly deploying APIs in Mule runtimes that are able to scale, connect to on-premises systems, and migrate as needed.
Following MuleSoft best practices, what MuleSoft runtime deployment option best meets the company’s goals to begin its digital transformation journey?
ACloudHub runtimes
BCustomer-hosted self-provisioned runtimes
CCustomer-hosted runtimes provisioned by a MuleSoft services partner