Your customers security team needs to understand how the Oracle Loader for Hadoop Connector writes data to the Oracle database.
Which service performs the actual writing?
AOLH agent
Breduce tasks
Cwrite tasks
Dmap tasks
ENameNode
Your customer needs to manage configuration information on the Big Data Appliance.
Which service would you choose?
ASparkPlug
BApacheManager
CZookeeper
DHive Server
EJobMonitor
You are helping your customer troubleshoot the use of the Oracle Loader for Hadoop Connector in online mode. You have performed steps 1, 2, 4, and 5.
STEP 1: Connect to the Oracle database and create a target table.
STEP 2: Log in to the Hadoop cluster (or client).
STEP 3: Missing step -
STEP 4: Create a shell script to run the OLH job.
STEP 5: Run the OLH job.
What step is missing between step 2 and step 4?
ADiagnose the job failure and correct the error.
BCopy the table metadata to the Hadoop system.
CCreate an XML configuration file.
DQuery the table to check the data.
ECreate an OLH metadata file.
The hdfs_stream script is used by the Oracle SQL Connector for HDFS to perform a specific task to access data.
What is the purpose of this script?
AIt is the preprocessor script for the Impala table.
BIt is the preprocessor script for the HDFS external table.
CIt is the streaming script that creates a database directory.
DIt is the preprocessor script for the Oracle partitioned table.
EIt defines the jar file that points to the directory where Hive is installed.
Question 6
Configuring and Managing Apache Hadoop
0
Question 7
Configuring and Managing Oracle Big Data SQL
Question 8
Configuring and Managing Apache Hadoop
Question 9
Planning and Installing Oracle Big Data Appliance
Question 10
Configuring and Managing Oracle Big Data SQL
Question 11
Configuring and Managing Apache Hadoop
Question 12
Configuring and Managing Apache Hadoop
Question 13
Configuring and Managing Oracle NoSQL Database
Question 14
Configuring and Managing Oracle Big Data SQL
Question 15
Configuring and Managing Oracle NoSQL Database
Question 16
Configuring and Managing Apache Hadoop
Question 17
Configuring and Managing Oracle NoSQL Database
Question 18
Configuring and Managing Oracle Big Data SQL
Question 19
Configuring and Managing Apache Hadoop
Question 20
Configuring and Managing Apache Hadoop
Question 21
Configuring Oracle Big Data Appliance
Question 22
Configuring and Managing Apache Hadoop
Question 23
Configuring and Managing Oracle Big Data SQL
Question 24
Configuring and Managing Apache Hadoop
Question 25
Configuring and Managing Apache Hadoop
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ad
Want a break from the ads?
Become a Supporter and enjoy a completely ad-free experience, plus unlock Learn Mode, Exam Mode, AstroTutor AI, and more.
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
How should you encrypt the Hadoop data that sits on disk?
AEnable Transparent Data Encryption by using the Mammoth utility.
BEnable HDFS Transparent Encryption by using bdacli on a Kerberos-secured cluster.
CEnable HDFS Transparent Encryption on a non-Kerberos secured cluster.
DEnable Audit Vault and Database Firewall for Hadoop by using the Mammoth utility.
What two things does the Big Data SQL push down to the storage cell on the Big Data Appliance? (Choose two.)
ATransparent Data Encrypted data
Bthe column selection of data from individual Hadoop nodes
CWHERE clause evaluations
DPL/SQL evaluation
EBusiness Intelligence queries from connected Exalytics servers
You want to set up access control lists on your NameNode in your Big Data Appliance. However, when you try to do so, you get an error stating "the NameNode disallows creation of ACLs."
What is the cause of the error?
ADuring the Big Data Appliance setup, Cloudera's ACLSecurity product was not installed.
BAccess control lists are set up on the DataNode and HadoopNode, not the NameNode.
CDuring the Big Data Appliance setup, the Oracle Audit Vault product was not installed.
Ddfs.namenode.acls.enabled must be set to true in the NameNode configuration.
Your customer has an older starter rack Big Data Appliance (BDA) that was purchased in 2013. The customer would like to know what the options are for growing the storage footprint of its server.
Which two options are valid for expanding the customers BDA footprint? (Choose two.)
AElastically expand the footprint by adding additional high capacity nodes.
BElastically expand the footprint by adding additional Big Data Oracle Database Servers.
CElastically expand the footprint by adding additional Big Data Storage Servers.
DRacks manufactured before 2014 are no longer eligible for expansion.
EUpgrade to a full 18-node Big Data Appliance.
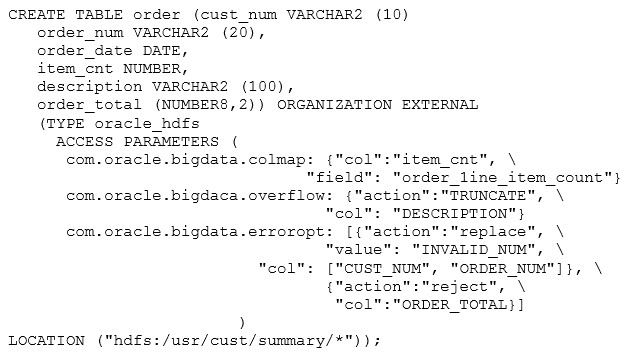
What are three correct results of executing the preceding query? (Choose three.)
AValues longer than 100 characters for the DESCRIPTION column are truncated.
BORDER_LINE_ITEM_COUNT in the HDFS file matches ITEM_CNT in the external table.
CITEM_CNT in the HDFS file matches ORDER_LINE_ITEM_COUNT in the external table.
DErrors in the data for CUST_NUM or ORDER_NUM set the value to INVALID_NUM.
EErrors in the data for CUST_NUM or ORDER_NUM set the value to 0000000000.
FValues longer than 100 characters for any column are truncated.
What does the following line do in Apache Pig?
products = LOAD /user/oracle/products AS (prod_id, item);
AThe products table is loaded by using data pump with prod_id and item.
BThe LOAD table is populated with prod_id and item.
CThe contents of /user/oracle/products are loaded as tuples and aliased to products.
DThe contents of /user/oracle/products are dumped to the screen.
What is the output of the following six commands when they are executed by using the Oracle XML Extensions for Hive in the Oracle XQuery for Hadoop
Connector?
hive> LOAD DATA LOCAL INPATH 'src.txt' OVERWRITE INTO TABLE src;
hive> SELECT * FROM src;
OK -
xxx
6. hive> SELECT xml_query ("x/y", "<x><y>123</y><z>456</z></x>") FROM src;
Axyz
B123
C456
Dxxx
Ex/y
The NoSQL KVStore experiences a node failure. One of the replicas is promoted to primary.
How will the NoSQL client that accesses the store know that there has been a change in the architecture?
AThe KVLite utility updates the NoSQL client with the status of the master and replica.
BKVStoreConfig sends the status of the master and replica to the NoSQL client.
CThe NoSQL admin agent updates the NoSQL client with the status of the master and replica.
DThe Shard State Table (SST) contains information about each shard and the master and replica status for the shard.
Your customer is experiencing significant degradation in the performance of Hive queries. The customer wants to continue using SQL as the main query language for the HDFS store.
Which option can the customer use to improve performance?
Anative MapReduce Java programs
BImpala
CHiveFastQL
DApache Grunt
Your customer keeps getting an error when writing a key/value pair to a NoSQL replica.
What is causing the error?
AThe master may be in read-only mode and as result, writes to replicas are not being allowed.
BThe replica may be out of sync with the master and is not able to maintain consistency.
CThe writes must be done to the master.
DThe replica is in read-only mode.
EThe data file for the replica is corrupt.
The log data for your customer's Apache web server has seven string columns.
What is the correct command to load the log data from the file 'sample.log' into a new Hive table LOGS that does not currently exist?
Ahive> CREATE TABLE logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ';
Bhive> create table logs as select * from sample.log;
Chive> CREATE TABLE logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '; hive> LOAD DATA LOCAL INPATH 'sample.log' OVERWRITE INTO TABLE logs;
Dhive> LOAD DATA LOCAL INPATH 'sample.log' OVERWRITE INTO TABLE logs; hive> CREATE TABLE logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ';
Ehive> create table logs as load sample.1og from hadoop;
Your customer’s Oracle NoSQL store has a replication factor of 3. One of the customer’s replica nodes goes down.
What will be the long-term performance impact on the customer’s NoSQL database if the node is replaced?
AThere will be no performance impact.
BThe database read performance will be impacted.
CThe database read and write performance will be impacted.
DThe database will be unavailable for reading or writing.
EThe database write performance will be impacted.
Your customer is using the IKM SQL to HDFS File (Sqoop) module to move data from Oracle to HDFS. However, the customer is experiencing performance issues.
What change should you make to the default configuration to improve performance?
AChange the ODI configuration to high performance mode.
BIncrease the number of Sqoop mappers.
CAdd additional tables.
DChange the HDFS server I/O settings to duplex mode.
What is the result when a flume event occurs for the following single node configuration?
AThe event is written to memory.
BThe event is logged to the screen.
CThe event output is not defined in this section.
DThe event is sent out on port 44444.
EThe event is written to the netcat process.
What kind of workload is MapReduce designed to handle?
Abatch processing
Binteractive
Ccomputational
Dreal time
Ecommodity
Your customer uses LDAP for centralized user/group management.
How will you integrate permissions management for the customers Big Data Appliance into the existing architecture?
AMake Oracle Identity Management for Big Data the single source of truth and point LDAP to its keystore for user lookup.
BEnable Oracle Identity Management for Big Data and point its keystore to the LDAP directory for user lookup.
CMake Kerberos the single source of truth and have LDAP use the Key Distribution Center for user lookup.
DEnable Kerberos and have the Key Distribution Center use the LDAP directory for user lookup.
Your customer collects diagnostic data from its storage systems that are deployed at customer sites. The customer needs to capture and process this data by country in batches.
Why should the customer choose Hadoop to process this data?
AHadoop processes data on large clusters (10-50 max) on commodity hardware.
BHadoop is a batch data processing architecture.
CHadoop supports centralized computing of large data sets on large clusters.
DNode failures can be dealt with by configuring failover with clusterware.
EHadoop processes data serially.
Your customer wants to architect a system that helps to make real-time recommendations to users based on their past search history.
Which solution should the customer use?
AOracle Container Database
BOracle Exadata
COracle NoSQL
DOracle Data Integrator
How should you control the Sqoop parallel imports if the data does not have a primary key?
Aby specifying no primary key with the --no-primary argument
Bby specifying the number of maps by using the –m option
Cby indicating the split size by using the --direct-split-size option
Dby choosing a different column that contains unique data with the --split-by argument
Your customer uses Active Directory to manage user accounts. You are setting up Hadoop Security for the customers Big Data Appliance.
How will you integrate Hadoop and Active Directory?
ASet up Kerberos’ Key Distribution Center to be the Active Directory keystore.
BConfigure Active Directory to use Kerberos’ Key Distribution Center.
CSet up a one-way cross-realm trust from the Kerberos realm to the Active Directory realm.
DSet up a one-way cross-realm trust from the Active Directory realm to the Kerberos realm.