DP-700: Implementing Data Engineering Solutions Using Microsoft FabricDemo
By Microsoft · Browse Mode
//
DP-700: Implementing Data Engineering Solutions Us… Practice Exam
QuestionQ1
Implement and manage an analytics solution
Save question
HOTSPOT –
You have a Fabric workspace named Workspace1_DEV that contains the following items:
10 reports
Four notebooks
Three lakehouses
Two data pipelines
Two Dataflow Gen1 dataflows
Three Dataflow Gen2 dataflows
Five semantic models, each with a scheduled refresh policy
You create a deployment pipeline named Pipeline1 to move items from Workspace1_DEV to a new workspace named Workspace1_TEST. You deploy every item from Workspace1_DEV to Workspace1_TEST.
For each statement, select Yes if it is true. Otherwise, select No.
Yes or No
Yes
No
Statements
Data from the semantic models will be deployed to the target stage.
The Dataflow Gen1 dataflows will be deployed to the target stage.
The scheduled refresh policies will be deployed to the target stage.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Ingest and transform data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Ingest and transform data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ4
Ingest and transform data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ5
Implement and manage an analytics solution
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
1
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database. The table includes the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be sorted by No_Bikes in ascending order.
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database. The table includes the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be sorted by No_Bikes in ascending order.
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database. The table includes the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be sorted by No_Bikes in ascending order.
0
Community Discussion
No comments yet. Be the first to start the discussion!
You have a Fabric workspace that includes a semantic model called Model1.
You need to dynamically run and monitor Model1's refresh progress.
What should you use?
Adynamic management views in Microsoft SQL Server Management Studio (SSMS)
BMonitoring hub
Cdynamic management views in Azure Data Studio
Da semantic link in a notebook
You have a Fabric workspace named Workspace1 that contains an Azure Data Factory pipeline named Pipeline1.
You need to monitor Pipeline1’s execution and activity status and automatically email an alert if the pipeline fails. The solution must minimize development and administrative effort.
What should you use to monitor Pipeline1, and what should you use to email the alert?
Select
Monitor Pipeline1:
Email alert:
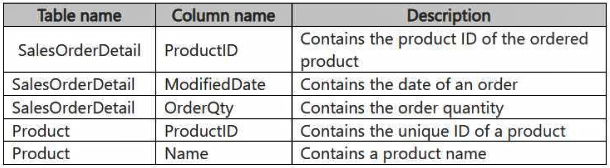
You have a Fabric workspace containing a warehouse named DW1. DW1 contains the following tables and columns.
You need to create output that shows summarized order quantities by year and product. The results must include an order-quantity summary at the year level across all products.
How should you complete the code?
Select
(SO.ModifiedDate) AS OrderDate
,P.Name AS ProductName
,SUM(SO.OrderQty) AS OrderQty
FROM [dbo].[SalesOrderDetail] SO
INNER JOIN [dbo].[Product] P
ON P.ProductID = SO.ProductID
GROUP BY
ORDER BY OrderDate
You have a Fabric workspace containing an eventstream named EventStream1. An EventStream1 transformation fails. You need to find the following error information:
Select
To find the error details:
To find the total number of errors:
You have a Fabric deployment pipeline that uses three workspaces named Dev, Test, and Prod.
You need to deploy an eventhouse as part of the deployment process.
What should you use to add the eventhouse to the deployment process?
AGitHub Actions
Ba deployment pipeline
Can Azure DevOps pipeline
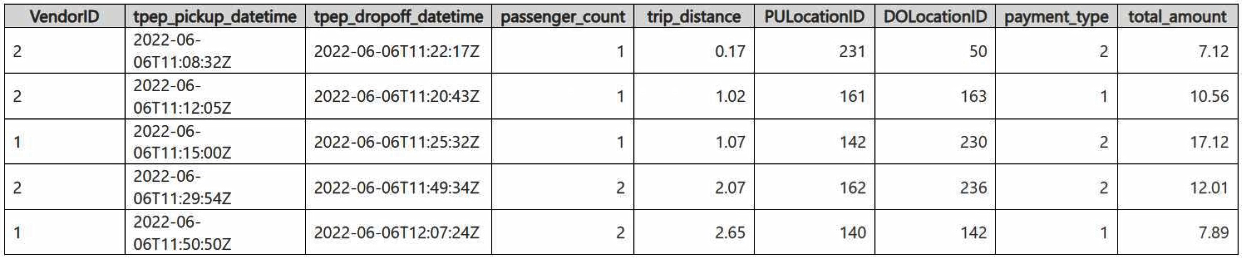
You have a Fabric eventhouse containing a KQL database. The database includes a table named TaxiData. The following shows a sample of the data in TaxiData.
You need to create two KQL queries. The solution must satisfy these requirements:
One query must partition RunningTotalAmount by VendorID.
The other query must create a FirstPickupDateTime column that displays the first value of each hour from tpep_pickup_datetime, partitioned by payment_type.
How should each query be completed? Each value can be used once, multiple times, or not at all.
You have a Fabric workspace named Workspace1 that contains a lakehouse named Lakehouse1.
You perform the following actions:
• Connect Workspace1 to a Git repository and select the main branch.
• Create a new branch named feature1 and modify Lakehouse1.
• Merge the changes from feature1 into the main branch.
You need to ensure that the changes are available in Workspace1. The solution must minimize changes to Workspace1.
What should you do?
ADisconnect Workspace1 from the Git repository and reconnect Workspace1 to the main branch.
BFrom Workspace1, select Source control, and then select Updates.
CFrom Workspace1, select Source control, and then select Commit.
DSwitch Workspace1 to the feature1 branch and refresh the workspace.
Your company’s sales department uses two Fabric workspaces, named Workspace1 and Workspace2.
The company decides to implement a domain strategy for organizing the workspaces.
You must ensure that a user can perform these tasks:
Create a new domain for the sales department.
Create two subdomains: one for the east region and one for the west region.
Assign Workspace1 to the east-region subdomain.
Assign Workspace2 to the west-region subdomain.
The solution must adhere to the principle of least privilege.
Which role should be assigned to the user?
Aworkspace Admin
Bdomain admin
Cdomain contributor
DFabric admin
You have a Fabric workspace that includes a lakehouse named Lakehouse1.
An external data source contains data files of 500 GB each. A new file is added each day.
You need to ingest the data into Lakehouse1 without applying transformations. The solution must meet the following requirements:
Trigger the process when a new file is added.
Provide the highest throughput.
Which type of item should you use to ingest the data?
AEventstream
BDataflow Gen2
CStreaming dataset
DData pipeline
A Fabric deployment pipeline uses three workspaces named Dev, Test, and Prod.
You need to deploy an Eventhouse as part of the deployment process.
What should you use to add the Eventhouse to that deployment process?
Aan Azure DevOps pipeline
Ban eventstream
CGitHub Actions
You have a Fabric workspace named Workspace1.
Your company obtains GitHub licenses.
You need to configure source control for Workpace1 to use GitHub. The solution must adhere to the principle of least privilege.
Which permissions are required to ensure that you can commit code to GitHub?
AActions (Read and write) and Contents (Read and write)
BActions (Read and write) only
CContents (Read and write) only
DContents (Read) and Commit statuses (Read and write)
You have a Fabric workspace that includes a lakehouse named Lakehouse1.
An external data source contains data files that are 500 GB each. One new file is added every day.
You need to ingest the data into Lakehouse1 without applying transformations. The solution must meet these requirements:
Trigger the process when a new file is added.
Provide the highest throughput.
Which type of item should you use to ingest the data?
AReflex
BEventstream
CNotebook
DKQL queryset
HOTSPOT
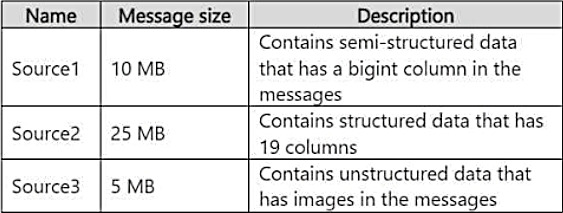
You need to recommend a Fabric streaming solution that uses the sources shown in the following table.
The solution must minimize development effort.
What should the recommendation include for each source?
Select
Source1:
Source2:
Source3:
You have a Fabric workspace named Workspace1 that includes an Apache Spark job definition named Job1.
You have an Azure SQL database named Source1 with public internet access disabled.
You need to ensure that Job1 can access the data in Source1.
What should you create?
Aan on-premises data gateway
Ba managed private endpoint
Can integration runtime
Da data management gateway
You have a Fabric workspace named Workspace1.
You plan to integrate Workspace1 with Azure DevOps.
You will use a Fabric deployment pipeline named deployPipeline1 to deploy items from Workspace1 to higher-environment workspaces as part of a medallion architecture. You will run deployPipeline1 by using an API call from an Azure DevOps pipeline.
You need to configure API authentication between Azure DevOps and Fabric.
Which authentication type should you use?
Aservice principal
BMicrosoft Entra username and password
Cmanaged private endpoint
Dworkspace identity
You have a Fabric warehouse named DW1. DW1 includes a table that stores sales data and is used by several sales representatives.
You plan to implement row-level security (RLS).
You need to ensure that sales representatives can view only their own data.
Which warehouse object is required to implement RLS?
ASECURITY POLICY
BTABLE
CTRIGGER
DSTORED PROCEDURE
What should you do to improve the query experience for the business users?




Community Discussion