Loading provider exams...
Loading provider exams...
Sign Up & unlock 100% of Exam Questions
No Strings Attached!
Updated
Case Study -
This is a case study. Case studies are not timed separately from other exam sections. You can use as much exam time as you would like to complete each case study. However, there might be additional case studies or other exam sections. Manage your time to ensure that you can complete all the exam sections in the time provided. Pay attention to the Exam Progress at the top of the screen so you have sufficient time to complete any exam sections that follow this case study.
To answer the case study questions, you will need to reference information that is provided in the case. Case studies and associated questions might contain exhibits or other resources that provide more information about the scenario described in the case. Information provided in an individual question does not apply to the other questions in the case study.
A Review Screen will appear at the end of this case study. From the Review Screen, you can review and change your answers before you move to the next exam section. After you leave this case study, you will NOT be able to return to it.
To start the case study -
To display the first question in this case study, select the "Next" button. To the left of the question, a menu provides links to information such as business requirements, the existing environment, and problem statements. Please read through all this information before answering any questions. When you are ready to answer a question, select the "Question" button to return to the question.
Background -
Fabrikam Inc. is a mid-sized healthcare analytics company that provides population health dashboards and predictive insights to regional hospital systems across the United States. Fabrikam Inc. customers rely on near real time analytics to monitor patient flow, staffing needs, and readmission risks. They use multiple traditional forecasting machine learning models for predictions.
Fabrikam Inc. has an established Microsoft Azure footprint. The company uses Jupyter Notebooks that run on a local server as the primary development environment. The data science team is experiencing scalability, asset management and code management issues with the current development platform. Fabrikam Inc. plans to migrate to a cloud-based development environment to mitigate the issues.
Additionally, the company plans to implement a Retrieval-Augmented Generation (RAG)-based chat application for client support. Leadership requires the application to be developed and deployed with a low operational risk.
Current Environment -
Fabrikam Inc. operates a single Azure subscription that has the following components:
Azure Data Lake Storage Gen2 that contains de-identified clinical and operational datasets
Azure AI Search indexing curated analytical documents and reference materials
A small set of Python-based training scripts maintained by data scientists
Azure OpenAI Service with deployed foundational models
A Microsoft Foundry resource for building a RAG-based solution
Evaluation data has manually defined expected responses.
The current challenges faced by the data science team include the following:
Model training jobs are run manually from notebooks.
Experiment tracking is inconsistent
Model versions are registered without standardized metadata.
Deployment is performed manually by data scientists, with limited rollback capability.
The team has no standardized evaluation process for generative AI outputs.
The environment currently allows public network access. Authentication relies on user accounts rather than managed identities. Compute targets are manually created and shared across experiments. This has led to resource contention during peak usage.
This exam has 60 community-verified practice questions. Create a free account to access all questions, comments, and explanations.
Log In / Sign UpBusiness Requirements -
Fabrikam Inc. has the following business requirements for the modernization initiative:
Provide a conversational interface that answers analytics questions by using internal documents and datasets.
Ensure that sensitive healthcare-related data is not exposed outside the Fabrikam Inc. Azure tenant.
Enable repeatable and auditable model training and deployment processes.
Support experimentation to compare prompt strategies and fine-tuned models.
Align the model with the ranked preferences and optimize behavior for the long term.
Minimize disruption to existing analytics workloads during rollout.
Technical Requirements -
To support the business goals, Fabrikam Inc. identifies these technical requirements:
Use Azure Machine Learning workspaces to centrally manage data assets, models, and environments.
Implement experiment tracking and model versioning for all training jobs.
Orchestrate training and evaluation by using pipelines rather than manually running notebooks.
Deploy traditional machine learning models with support for staged rollout and rollback.
Improve RAG-based solution output quality.
Use the existing evaluation datasets that are based on real data with input-output pairs.
Apply advanced fine-tuning techniques only when prompt engineering is insufficient
Issues and Constraints -
Fabrikam Inc. must comply with internal security policies that require the company to restrict network access and avoid long-lived secrets. The data science team has limited Azure DevOps experience, so solutions must favor managed services and automation over custom infrastructure.
Cost predictability is important. Leadership prefers serverless or managed compute options where possible but is willing to approve dedicated compute for stable production workloads.
Problem Statement -
Fabrikam Inc. must design and implement an Azure-based AI operations solution that enables reliable training, evaluation, deployment, and iteration of generative AI models. The solution must support experimentation and gradual rollout while ensuring governance, security, and operational stability. The data science and platform teams must collaborate to deliver this solution by using Azure Machine Learning and Microsoft Foundry capabilities.
You need to standardize how Fabrikam Inc. manages machine learning assets.
Which action should you perform first?
Case Study -
This is a case study. Case studies are not timed separately from other exam sections. You can use as much exam time as you would like to complete each case study. However, there might be additional case studies or other exam sections. Manage your time to ensure that you can complete all the exam sections in the time provided. Pay attention to the Exam Progress at the top of the screen so you have sufficient time to complete any exam sections that follow this case study.
To answer the case study questions, you will need to reference information that is provided in the case. Case studies and associated questions might contain exhibits or other resources that provide more information about the scenario described in the case. Information provided in an individual question does not apply to the other questions in the case study.
A Review Screen will appear at the end of this case study. From the Review Screen, you can review and change your answers before you move to the next exam section. After you leave this case study, you will NOT be able to return to it.
To start the case study -
To display the first question in this case study, select the "Next" button. To the left of the question, a menu provides links to information such as business requirements, the existing environment, and problem statements. Please read through all this information before answering any questions. When you are ready to answer a question, select the "Question" button to return to the question.
Background -
Fabrikam Inc. is a mid-sized healthcare analytics company that provides population health dashboards and predictive insights to regional hospital systems across the United States. Fabrikam Inc. customers rely on near real time analytics to monitor patient flow, staffing needs, and readmission risks. They use multiple traditional forecasting machine learning models for predictions.
Fabrikam Inc. has an established Microsoft Azure footprint. The company uses Jupyter Notebooks that run on a local server as the primary development environment. The data science team is experiencing scalability, asset management and code management issues with the current development platform. Fabrikam Inc. plans to migrate to a cloud-based development environment to mitigate the issues.
Additionally, the company plans to implement a Retrieval-Augmented Generation (RAG)-based chat application for client support. Leadership requires the application to be developed and deployed with a low operational risk.
Current Environment -
Fabrikam Inc. operates a single Azure subscription that has the following components:
Azure Data Lake Storage Gen2 that contains de-identified clinical and operational datasets
Azure AI Search indexing curated analytical documents and reference materials
A small set of Python-based training scripts maintained by data scientists
Azure OpenAI Service with deployed foundational models
A Microsoft Foundry resource for building a RAG-based solution
Evaluation data has manually defined expected responses.
The current challenges faced by the data science team include the following:
Model training jobs are run manually from notebooks.
Experiment tracking is inconsistent
Model versions are registered without standardized metadata.
Deployment is performed manually by data scientists, with limited rollback capability.
The team has no standardized evaluation process for generative AI outputs.
The environment currently allows public network access. Authentication relies on user accounts rather than managed identities. Compute targets are manually created and shared across experiments. This has led to resource contention during peak usage.
Business Requirements -
Fabrikam Inc. has the following business requirements for the modernization initiative:
Provide a conversational interface that answers analytics questions by using internal documents and datasets.
Ensure that sensitive healthcare-related data is not exposed outside the Fabrikam Inc. Azure tenant.
Enable repeatable and auditable model training and deployment processes.
Support experimentation to compare prompt strategies and fine-tuned models.
Align the model with the ranked preferences and optimize behavior for the long term.
Minimize disruption to existing analytics workloads during rollout.
Technical Requirements -
To support the business goals, Fabrikam Inc. identifies these technical requirements:
Use Azure Machine Learning workspaces to centrally manage data assets, models, and environments.
Implement experiment tracking and model versioning for all training jobs.
Orchestrate training and evaluation by using pipelines rather than manually running notebooks.
Deploy traditional machine learning models with support for staged rollout and rollback.
Improve RAG-based solution output quality.
Use the existing evaluation datasets that are based on real data with input-output pairs.
Apply advanced fine-tuning techniques only when prompt engineering is insufficient
Issues and Constraints -
Fabrikam Inc. must comply with internal security policies that require the company to restrict network access and avoid long-lived secrets. The data science team has limited Azure DevOps experience, so solutions must favor managed services and automation over custom infrastructure.
Cost predictability is important. Leadership prefers serverless or managed compute options where possible but is willing to approve dedicated compute for stable production workloads.
Problem Statement -
Fabrikam Inc. must design and implement an Azure-based AI operations solution that enables reliable training, evaluation, deployment, and iteration of generative AI models. The solution must support experimentation and gradual rollout while ensuring governance, security, and operational stability. The data science and platform teams must collaborate to deliver this solution by using Azure Machine Learning and Microsoft Foundry capabilities.
You need to isolate training workloads while remaining cost-aware to address Fabrikam Inc.’s issues, constraints, and technical requirements.
What should you implement?
You manage an Azure Machine learning workspace. You develop a machine learning model.
You must deploy the model to use a low-priority VM with a pricing discount.
You need to deploy the model.
Which compute target should you use?
A team manages an Azure Machine Learning workspace where they deploy models to online endpoints.
The team needs to introduce a new version of a model to production without disrupting existing users.
The team must validate the new version before full rollout.
You need to reduce risk during deployment.
What should you do?
You have a deployment of an Azure OpenAI Service base model.
You plan to fine-tune the model.
You need to prepare a file that contains training data.
Which file format should you use?
You have a deployment of an Azure OpenAI Service base model.
You plan to fine-tune the model.
You need to prepare a file that contains training data for multi-turn chat.
Which file encoding method should you use?
Want a break from the ads?
Become a Supporter and enjoy a completely ad-free experience, plus unlock Learn Mode, Exam Mode, AstroTutor AI, and more.
HOTSPOT -
A team trains an MLflow model that scores customer churn risk. The model will be consumed by different downstream systems.
One system requests predictions synchronously during customer interactions.
Another system submits files containing millions of records for scheduled scoring.
You need to deploy the model by using managed inference options that match each usage pattern.
Which option should you use for each usage pattern? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You are fine-tuning a base language model to analyze customer feedback.
You label examples of support tickets. You must improve classification accuracy by configuring and fine-tuning the base model in Microsoft Foundry.
You need to configure and run fine-tuning.
What should you do first?
A team is working in Microsoft Foundry to test and compare large language model (LLM) prompt variants in a development environment.
The team requires consistent inputs to evaluate prompt variants without relying on live user traffic.
You need to create a controlled evaluation of input data.
Which action should you perform first?
An organization maintains separate Azure Machine Learning workspaces for development and production.
Both environments must use the same validated assets without duplicating them.
Assets must be shared across workspaces while maintaining centralized governance and version control.
You need to enable reuse of assets across workspaces without copying them.
What should you do?
An Azure Machine Learning workspace processes sensitive training data.
The workspace must NOT be accessible from the public internet.
You need to restrict network access.
Which configuration should you implement?
A team is experimenting with traditional models for a classification workflow in Azure Machine Learning.
The team requires a consistent way to manage assets that are created during experimentation.
You need to ensure that artifacts can be reused and governed across projects.
Which asset should you register?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear on the review screen.
You manage an Azure Machine Learning workspace. The Python script named script.py reads an argument named training_data. The training_data argument specifies the path to the training data in a file named dataset1.csv.
You plan to run the script.py Python script as a command job that trains a machine learning model.
You need to provide the command to pass the path for the dataset as a parameter value when you submit the script as a training job.
Solution: python train.py --training_data training_data
Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear on the review screen.
You manage an Azure Machine Learning workspace. The Python script named script.py reads an argument named training_data. The training_data argument specifies the path to the training data in a file named dataset1.csv.
You plan to run the script.py Python script as a command job that trains a machine learning model.
You need to provide the command to pass the path for the dataset as a parameter value when you submit the script as a training job.
Solution:
python script.py --trainingdata ${{inputs.training_data}}
Does the solution meet the goal?
DRAG DROP -
A team maintains Infrastructure as Code (IaC) templates to provision Azure Machine Learning resources.
Provisioning must be triggered by changes in the templates and executed without manual intervention.
You need to automate resource provisioning.
Which action should you take for each requirement? To answer, move the appropriate actions to the correct requirements. You may use each action once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear on the review screen.
You manage an Azure Machine Learning workspace. The Python script named script.py reads an argument named training_data. The training_data argument specifies the path to the training data in a file named dataset1.csv.
You plan to run the script.py Python script as a command job that trains a machine learning model.
You need to provide the command to pass the path for the dataset as a parameter value when you submit the script as a training job.
Solution: python script.py dataset1.csv
Does the solution meet the goal?
Case Study -
This is a case study. Case studies are not timed separately from other exam sections. You can use as much exam time as you would like to complete each case study. However, there might be additional case studies or other exam sections. Manage your time to ensure that you can complete all the exam sections in the time provided. Pay attention to the Exam Progress at the top of the screen so you have sufficient time to complete any exam sections that follow this case study.
To answer the case study questions, you will need to reference information that is provided in the case. Case studies and associated questions might contain exhibits or other resources that provide more information about the scenario described in the case. Information provided in an individual question does not apply to the other questions in the case study.
A Review Screen will appear at the end of this case study. From the Review Screen, you can review and change your answers before you move to the next exam section. After you leave this case study, you will NOT be able to return to it.
To start the case study -
To display the first question in this case study, select the "Next" button. To the left of the question, a menu provides links to information such as business requirements, the existing environment, and problem statements. Please read through all this information before answering any questions. When you are ready to answer a question, select the "Question" button to return to the question.
Background -
Fabrikam Inc. is a mid-sized healthcare analytics company that provides population health dashboards and predictive insights to regional hospital systems across the United States. Fabrikam Inc. customers rely on near real time analytics to monitor patient flow, staffing needs, and readmission risks. They use multiple traditional forecasting machine learning models for predictions.
Fabrikam Inc. has an established Microsoft Azure footprint. The company uses Jupyter Notebooks that run on a local server as the primary development environment. The data science team is experiencing scalability, asset management and code management issues with the current development platform. Fabrikam Inc. plans to migrate to a cloud-based development environment to mitigate the issues.
Additionally, the company plans to implement a Retrieval-Augmented Generation (RAG)-based chat application for client support. Leadership requires the application to be developed and deployed with a low operational risk.
Current Environment -
Fabrikam Inc. operates a single Azure subscription that has the following components:
Azure Data Lake Storage Gen2 that contains de-identified clinical and operational datasets
Azure AI Search indexing curated analytical documents and reference materials
A small set of Python-based training scripts maintained by data scientists
Azure OpenAI Service with deployed foundational models
A Microsoft Foundry resource for building a RAG-based solution
Evaluation data has manually defined expected responses.
The current challenges faced by the data science team include the following:
Model training jobs are run manually from notebooks.
Experiment tracking is inconsistent
Model versions are registered without standardized metadata.
Deployment is performed manually by data scientists, with limited rollback capability.
The team has no standardized evaluation process for generative AI outputs.
The environment currently allows public network access. Authentication relies on user accounts rather than managed identities. Compute targets are manually created and shared across experiments. This has led to resource contention during peak usage.
Business Requirements -
Fabrikam Inc. has the following business requirements for the modernization initiative:
Provide a conversational interface that answers analytics questions by using internal documents and datasets.
Ensure that sensitive healthcare-related data is not exposed outside the Fabrikam Inc. Azure tenant.
Enable repeatable and auditable model training and deployment processes.
Support experimentation to compare prompt strategies and fine-tuned models.
Align the model with the ranked preferences and optimize behavior for the long term.
Minimize disruption to existing analytics workloads during rollout.
Technical Requirements -
To support the business goals, Fabrikam Inc. identifies these technical requirements:
Use Azure Machine Learning workspaces to centrally manage data assets, models, and environments.
Implement experiment tracking and model versioning for all training jobs.
Orchestrate training and evaluation by using pipelines rather than manually running notebooks.
Deploy traditional machine learning models with support for staged rollout and rollback.
Improve RAG-based solution output quality.
Use the existing evaluation datasets that are based on real data with input-output pairs.
Apply advanced fine-tuning techniques only when prompt engineering is insufficient
Issues and Constraints -
Fabrikam Inc. must comply with internal security policies that require the company to restrict network access and avoid long-lived secrets. The data science team has limited Azure DevOps experience, so solutions must favor managed services and automation over custom infrastructure.
Cost predictability is important. Leadership prefers serverless or managed compute options where possible but is willing to approve dedicated compute for stable production workloads.
Problem Statement -
Fabrikam Inc. must design and implement an Azure-based AI operations solution that enables reliable training, evaluation, deployment, and iteration of generative AI models. The solution must support experimentation and gradual rollout while ensuring governance, security, and operational stability. The data science and platform teams must collaborate to deliver this solution by using Azure Machine Learning and Microsoft Foundry capabilities.
You need to recommend an experiment-tracking strategy that ensures consistent experiment results.
What should you recommend?
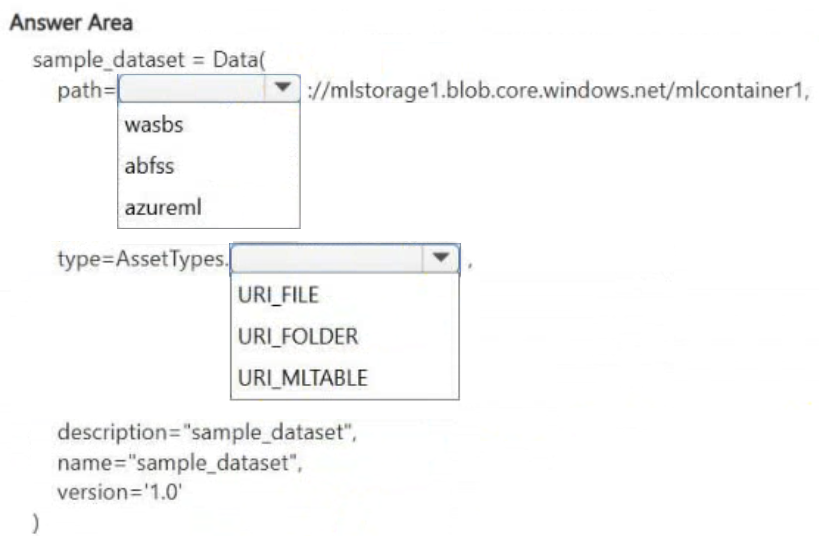
HOTSPOT -
You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2. You create a General Purpose v2 Azure storage account named mlstorage1. The storage account includes a publicly accessible container named mlcontainer1. The container stores 10 blobs with files in the CSV format.
You must develop Python SDK v2 code to create a data asset referencing all blobs in the container named mlcontainer1.
You need to complete the Python SDK v2 code.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
A team deploys a model to a real-time endpoint in Azure Machine Learning. You deploy some updates to the endpoint.
The endpoint returns errors after the new deployment is released.
You need to restore the service as quickly as possible.
What should you do first?
A data science team completes multiple training runs within an experiment by using MLflow.
The team wants to store a selected model in Azure Machine Learning so that it can be versioned and deployed later.
The model must be versioned centrally for reuse across environments.
You need to version the trained model.
Which two actions should you perform? Each correct answer presents part of the solution. Choose two.
NOTE: Each correct selection is worth one point.
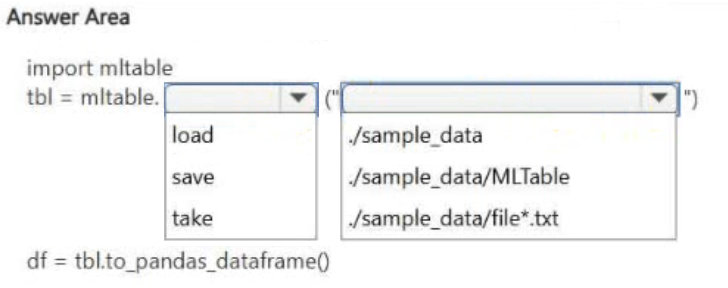
HOTSPOT -
You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2.
The default datastore of workspace1 contains a folder named sample_data. The folder structure contains the following content:

You write Python SDK v2 code to materialize the data from the files in the sample_data folder into a Pandas data frame.
You need to complete the Python SDK v2 code to use the MLTable folder as the materialization blueprint.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
An Azure Machine Learning workspace contains multiple registered versions of a model that is used in production.
An older model version must no longer be deployable, but it must remain available for compliance review and potential rollback.
You need to change the state of the model version to meet the requirements.
What should you do?
A team is deploying machine learning models to a production inference endpoint in Azure Machine Learning.
The team requires a safe way to validate a new model version without disrupting existing users.
You need to recommend a deployment strategy for controlled testing of a new model version.
What should you configure?
HOTSPOT -
You train a model in Azure Machine Learning.
You plan to capture experiment details for later comparison. The training code must log parameters and metrics for each run.
You review the following training script.

You need to verify whether the training script meets the experiment tracking requirement. For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
