Loading questions...
Loading questions...
Updated
Want a break from the ads?
Become a Supporter and enjoy a completely ad-free experience, plus unlock Learn Mode, Exam Mode, AstroTutor AI, and more.
Support Examcademy
Your support keeps this platform running. Become a Supporter to remove all ads and unlock exclusive study tools.
Create a free account to unlock all questions for this exam.
Log In / Sign UpNote: This question is part of series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.

You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You add conditions to the policy.
Does this meet the goal?
Note: This question is part of series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.

You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You change the external attribute to true.
Does this meet the goal?
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
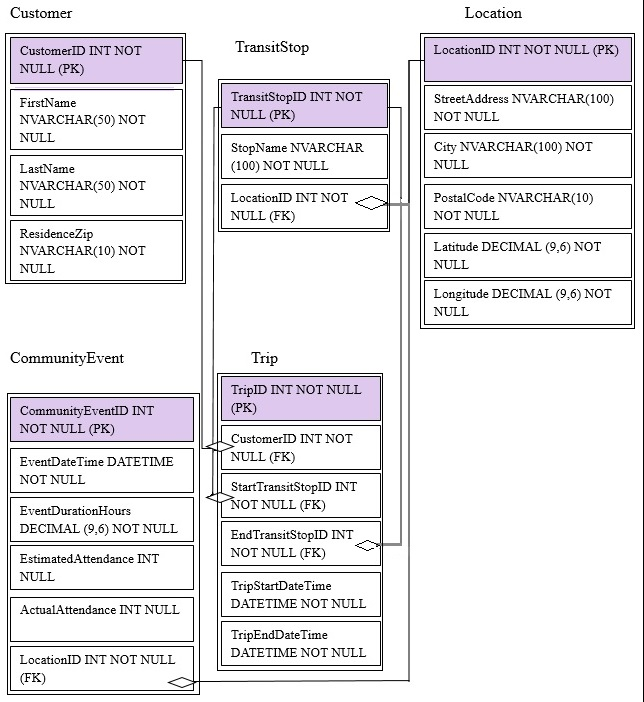
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.

You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
You plan to create the Azure Data Factory pipeline.
Which activity requires that you create a custom activity?
DRAG DROP -
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
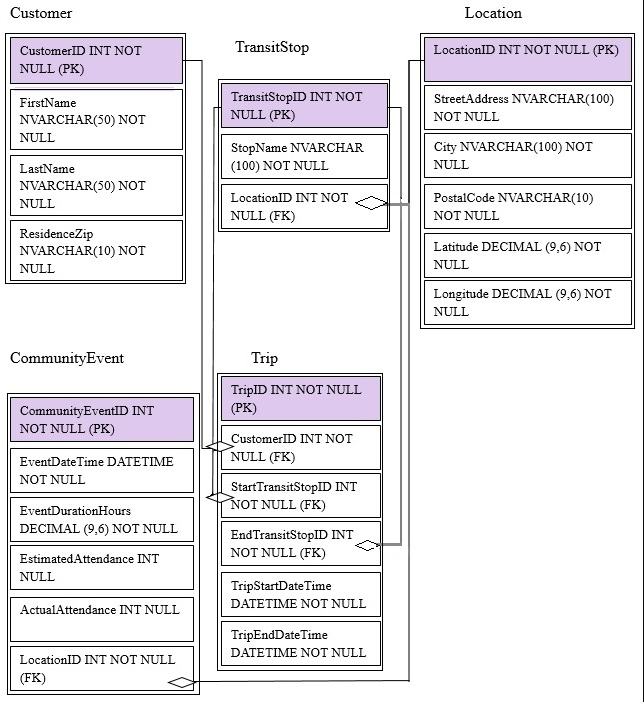
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.

You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
Which types of threat detection should you configure for each threat pattern? To answer, drag the appropriate threat detection types to the correct patterns. Each threat detection type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
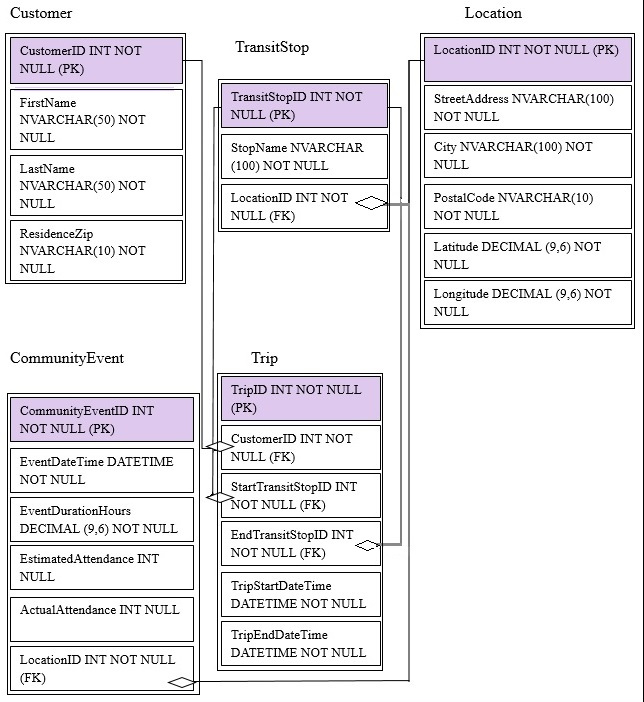
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.

You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
You need to copy the weather data for June 2016 to StorageAccount1.
Which command should you run on AzureVM1?
You are designing a data loading process for a Microsoft Azure SQL data warehouse. Data will be loaded to Azure Blob storage, and then the data will be loaded to the data warehouse.
Which tool should you use to load the data to Azure Blob storage?
You have a Microsoft Azure SQL data warehouse to which 1,000 Data Warehouse Units (DWUs) are allocated.
You plan to load 10 million rows of data to the data warehouse.
You need to load the data in the least amount of time possible. The solution must ensure that queries against the new data execute as quickly as possible.
What should you use to optimize the data load?
You have a Microsoft Azure SQL data warehouse stored in geo-redundant storage.
You experience a regional outage.
You plan to recover the database to a new region.
You need to get a list of the backup files that can be restored to the new region.
Which cmdlet should you run?
HOTSPOT -
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
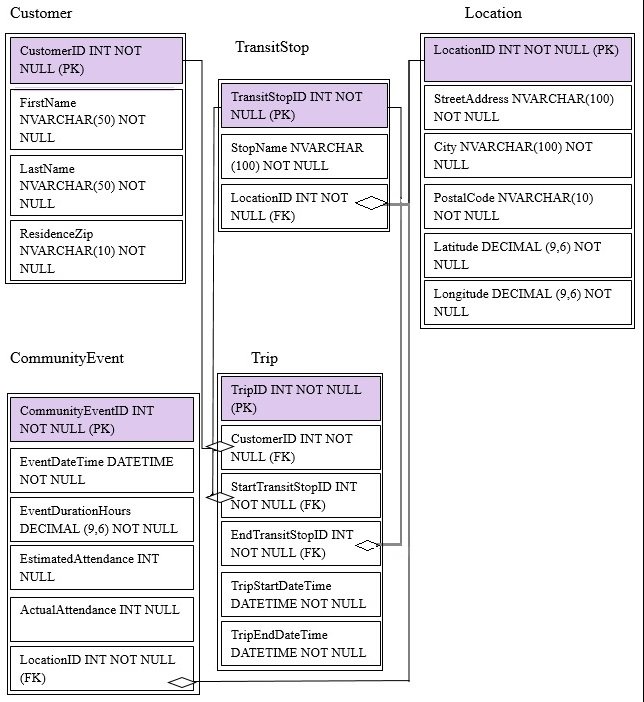
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.

You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
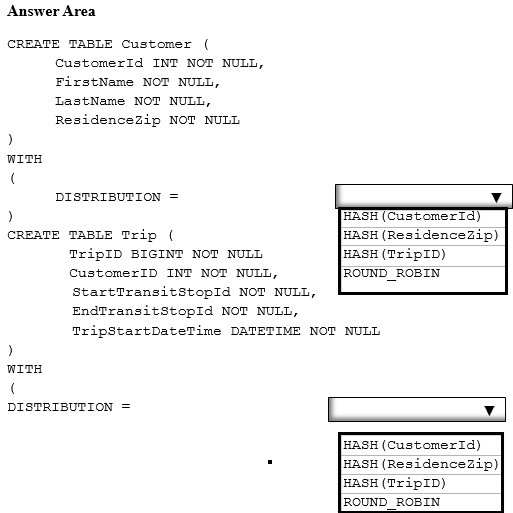
You plan to create a report that will query customer records for a selected ResidenceZip. The report will return customer trips sorted by TripStartDateTime.
You need to specify the distribution clause for each table. The solution must meet the following requirements.
✑ Minimize how long it takes to query the customer information.
✑ Perform the operation as a pass-through query without data movement.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You manage an on-premises data warehouse that uses Microsoft SQL Server. The data warehouse contains 100 TB of data. The data is partitioned by month.
One TB of data is added to the data warehouse each month.
You create A Microsoft Azure SQL data warehouse and copy the on-premises data to the data warehouse.
You need to implement a process to replicate the on-premises data warehouse to the Azure SQL data warehouse. The solution must support daily incremental updates and must provide error handling.
What should you use?
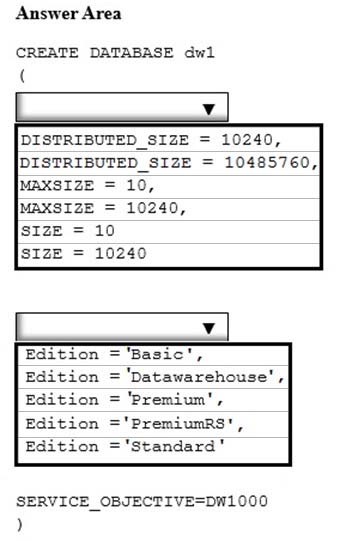
HOTSPOT -
You need to create a Microsoft Azure SQL data warehouse named dw1 that supports up to 10 TB of data.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You have a Microsoft Azure SQL data warehouse named DW1 that is used only from Monday to Friday.
You need to minimize Data Warehouse Unit (DWU) usage during the weekend.
What should you do?
You plan to deploy a Microsoft Azure virtual machine that will a host data warehouse. The data warehouse will contain a 10-TB database.
You need to provide the fastest read and writes times for the database.
Which disk configuration should you use?
You have a Microsoft Azure SQL data warehouse that has a fact table named FactOrder. FactOrder contains three columns named CustomerID, OrderID, and
OrderDateKey. FactOrder is hash distributed on CustomerID. OrderID is the unique identifier for FactOrder. FactOrder contains 3 million rows.
Orders are distributed evenly among different customers from a table named dimCustomers that contains 2 million rows.
You often run queries that join FactOrder and dimCustomers by selecting and grouping by the OrderDateKey column.
You add 7 million rows to FactOrder. Most of the new records have a more recent OrderDateKey value than the previous records.
You need to reduce the execution time of queries that group on OrderDateKey and that join dimCustomers and FactOrder.
What should you do?
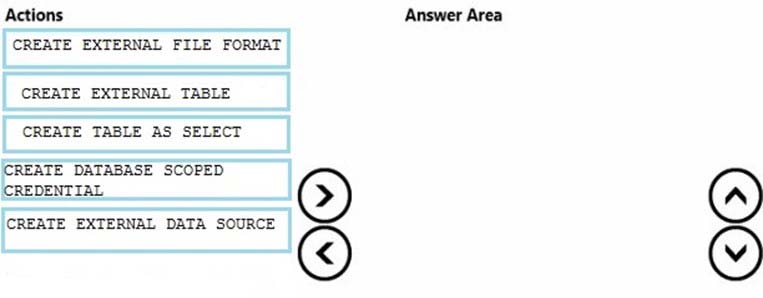
DRAG DROP -
You have a Microsoft Azure SQL data warehouse.
You plan to reference data from Azure Blob storage. The data is stored in the GZIP compressed format. The blob storage requires authentication.
You create a master key for the data warehouse and a database schema.
You need to reference the data without importing the data to the data warehouse.
Which four statements should you execute in sequence? To answer, move the appropriate statements from the list of statements to the answer area and arrange them in the correct order.
Select and Place:
You need to connect to a Microsoft Azure SQL data warehouse from an Azure Machine Learning experiment.
Which data source should you use?