Professional Data Engineer Practice Exam — Free Google Questions
QuestionQ1
Ingesting and processing the data
Save question
You analyze user clickstream data to personalize content recommendations. The data arrives continuously and must be processed with low latency, including transformations such as sessionization (grouping clicks by user within a time window) and aggregation of user activity. You need to identify a scalable solution that can handle millions of events per second and remain resilient to late-arriving data. What should you do?
AUse Firebase Realtime Database for ingestion and storage, and Cloud Run functions for processing and analytics.
BUse Cloud Data Fusion for ingestion and transformation, and Cloud SQL for storage and analytics.
CUse Pub/Sub for ingestion, Dataflow with Apache Beam for processing, and BigQuery for storage and analytics.
DUse Cloud Storage for ingestion, Dataproc with Apache Spark for batch processing, and BigQuery for storage and analytics.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Ingesting and processing the data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Designing data processing systems
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ4
Ingesting and processing the data
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ5
Preparing and using data for analysis
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
Designing data processing systemsIngesting and processing the dataStoring the dataPreparing and using data for analysisMaintaining and automating data workloads
A web server publishes click events as messages to a Pub/Sub topic. The server includes an eventTimestamp attribute in each message that records when the click occurred. You have a Dataflow streaming job that reads this Pub/Sub topic through a subscription, performs some transformations, and writes the results to another Pub/Sub topic for the advertising department.
The advertising department must receive every message within 30 seconds of its corresponding click, but reports that messages arrive late. Your Dataflow job has system lag of about 5 seconds and data freshness of about 40 seconds. Inspection of several messages shows no more than 1 second of lag between eventTimestamp and publishTime. What is the issue, and what should you do?
AThe advertising department is causing delays when consuming the messages. Work with the advertising department to fix this.
BMessages in your Dataflow job are taking more than 30 seconds to process. Optimize your job or increase the number of workers to fix this.
DThe web server is not pushing messages fast enough to Pub/Sub. Work with the web server team to fix this.
You run a logistics company and want to make event delivery from vehicle-based sensors more reliable. You operate small data centers worldwide to capture these events, but the leased lines connecting your event-collection infrastructure to your event-processing infrastructure are unreliable and have unpredictable latency. You want to resolve this in the most cost-effective manner. What should you do?
ADeploy small Kafka clusters in your data centers to buffer events.
BHave the data acquisition devices publish data to Cloud Pub/Sub.
CEstablish a Cloud Interconnect between all remote data centers and Google.
DWrite a Cloud Dataflow pipeline that aggregates all data in session windows.
You have a BigQuery table that receives data directly from a Pub/Sub subscription. The ingested data is encrypted using a Google-managed encryption key. You must comply with a new organization policy requiring keys from a centralized Cloud Key Management Service (Cloud KMS) project to encrypt data at rest. What should you do?
AUse Cloud KMS encryption key with Dataflow to ingest the existing Pub/Sub subscription to the existing BigQuery table.
BCreate a new BigQuery table by using customer-managed encryption keys (CMEK), and migrate the data from the old BigQuery table.
CCreate a new Pub/Sub topic with CMEK and use the existing BigQuery table by using Google-managed encryption key.
DCreate a new BigQuery table and Pub/Sub topic by using customer-managed encryption keys (CMEK), and migrate the data from the old BigQuery table.
You monitor and optimize your team’s BigQuery instance. A particular daily report that uses a large JOIN operation is consistently slow. You want to inspect the query’s execution plan to identify potential performance bottlenecks within the JOIN as quickly as possible. What should you do?
AUse the bg query --dry_run command to review the estimated number of bytes read and review query syntax.
BRun a query on the INFORMATION_SCHEMA.JOBS_BY_PROJECT view filtering by the job_ID and analyze total_bytes_processed.
CReview the BigQuery audit logs in Cloud Logging.
DLeverage BigQuery's Query History view and analyze the execution graph.
QuestionQ6
Preparing and using data for analysis
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ7
Storing the data
QuestionQ8
Preparing and using data for analysis
QuestionQ9
Maintaining and automating data workloads
QuestionQ10
Maintaining and automating data workloads
QuestionQ11
Maintaining and automating data workloads
QuestionQ12
Storing the data
QuestionQ13
Storing the data
QuestionQ14
Designing data processing systems
QuestionQ15
Storing the data
QuestionQ16
Maintaining and automating data workloads
QuestionQ17
Ingesting and processing the data
QuestionQ18
Preparing and using data for analysis
QuestionQ19
Maintaining and automating data workloads
QuestionQ20
Maintaining and automating data workloads
QuestionQ21
Ingesting and processing the data
QuestionQ22
Preparing and using data for analysis
QuestionQ23
Preparing and using data for analysis
QuestionQ24
Maintaining and automating data workloads
QuestionQ25
Designing data processing systems
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
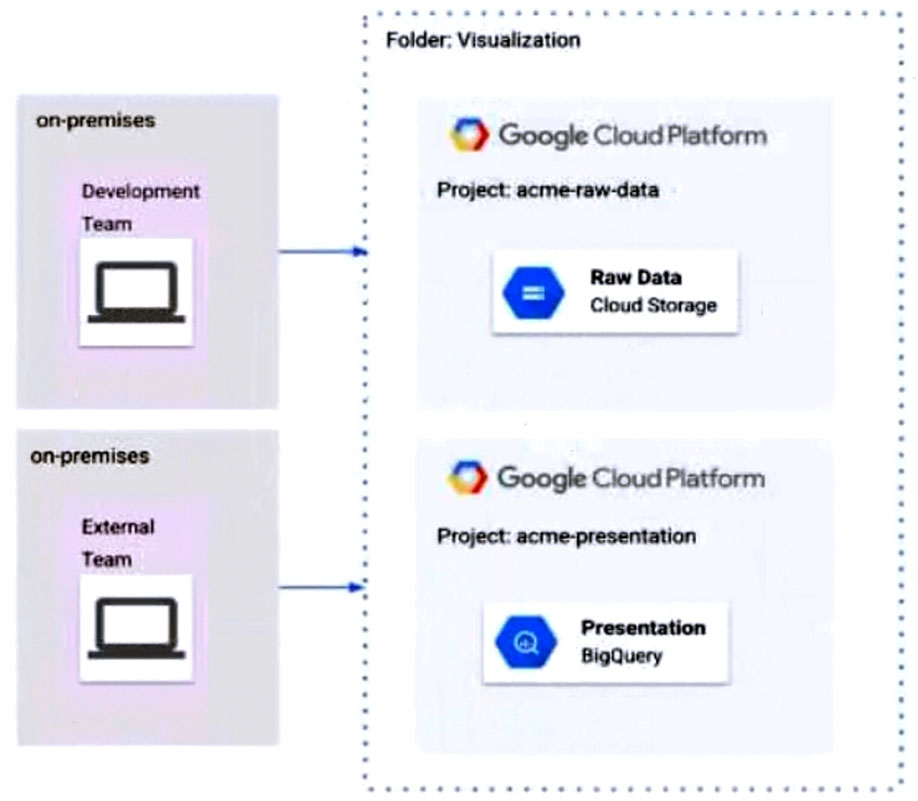
The Development and External teams have the Project Viewer Identity and Access Management (IAM) role in a folder called Visualization. You want the Development Team to be able to read data from both Cloud Storage and BigQuery, while the External Team can read data only from BigQuery. What should you do?
ARemove Cloud Storage IAM permissions to the External Team on the acme-raw-data project.
BCreate Virtual Private Cloud (VPC) firewall rules on the acme-raw-data project that deny all ingress traffic from the External Team CIDR range.
CCreate a VPC Service Controls perimeter containing both projects and BigQuery as a restricted API. Add the External Team users to the perimeter's Access Level.
DCreate a VPC Service Controls perimeter containing both projects and Cloud Storage as a restricted API. Add the Development Team users to the perimeter's Access Level.
Your company is migrating its 30-node Apache Hadoop cluster to the cloud. It wants to reuse Hadoop jobs it has already created and minimize cluster management as much as possible. It also needs to persist data beyond the cluster’s lifetime. What should you do?
ACreate a Google Cloud Dataflow job to process the data.
BCreate a Google Cloud Dataproc cluster that uses persistent disks for HDFS.
CCreate a Hadoop cluster on Google Compute Engine that uses persistent disks.
DCreate a Cloud Dataproc cluster that uses the Google Cloud Storage connector.
ECreate a Hadoop cluster on Google Compute Engine that uses Local SSD disks.
You currently use a SQL-based tool to visualize data stored in BigQuery. The data visualizations require outer joins and analytic functions. Visualizations must be based on data that is at least 4 hours old. Business users report that the visualizations take too long to generate. You want to improve the visualization-query performance while minimizing maintenance overhead for the data-preparation pipeline. What should you do?
ACreate materialized views with the allow_non_incremental_definition option set to true for the visualization queries. Specify the max_staleness parameter to 4 hours and the enable_refresh parameter to true. Reference the materialized views in the data visualization tool.
BCreate views for the visualization queries. Reference the views in the data visualization tool.
CCreate a Cloud Function instance to export the visualization query results as parquet files to a Cloud Storage bucket. Use Cloud Scheduler to trigger the Cloud Function every 4 hours. Reference the parquet files in the data visualization tool.
DCreate materialized views for the visualization queries. Use the incremental updates capability of BigQuery materialized views to handle changed data automatically. Reference the materialized views in the data visualization tool.
You are moving a large number of files from a public HTTPS endpoint to Cloud Storage. The files are safeguarded from unauthorized access by using signed URLs. You created a TSV file containing the object-URL list and started a transfer job using Storage Transfer Service. You observe that the job ran for a long time and ultimately failed. The transfer-job logs show that it was running successfully until a certain point, after which it failed with HTTP 403 errors for the remaining files. You confirmed that the source system had not changed. You need to resolve the issue so that you can resume the migration process. What should you do?
ASet up Cloud Storage FUSE, and mount the Cloud Storage bucket on a Compute Engine instance. Remove the completed files from the TSV file. Use a shell script to iterate through the TSV file and download the remaining URLs to the FUSE mount point.
BRenew the TLS certificate of the HTTPS endpoint. Remove the completed files from the TSV file and rerun the Storage Transfer Service job.
CCreate a new TSV file for the remaining files by generating signed URLs with a longer validity period. Split the TSV file into multiple smaller files and submit them as separate Storage Transfer Service jobs in parallel.
DUpdate the file checksums in the TSV file from using MD5 to SHA256. Remove the completed files from the TSV file and rerun the Storage Transfer Service job.
You need to orchestrate a pipeline across several Google Cloud services: a batch Dataflow job, followed by a BigQuery query job and then a Vertex AI batch prediction. The logic is sequential. You want a lightweight, serverless orchestration solution with minimal operational overhead. Which service should you use?
ASelect Cloud Composer.
BSelect Compute Engine with cron.
CSelect Dataproc with Apache Oozie.
DSelect Cloud Workflows.
You need to create a SQL pipeline. The pipeline performs an aggregate SQL transformation on a BigQuery table every two hours and appends the result to another existing BigQuery table. You must configure the pipeline to retry when errors occur. You want it to send an email notification after three consecutive failures. What should you do?
AUse the BigQueryUpsertTableOperator in Cloud Composer, set the retry parameter to three, and set the email_on_failure parameter to true.
BUse the BigQueryInsertJobOperator in Cloud Composer, set the retry parameter to three, and set the email_on_failure parameter to true.
CCreate a BigQuery scheduled query to run the SQL transformation with schedule options that repeats every two hours, and enable email notifications.
DCreate a BigQuery scheduled query to run the SQL transformation with schedule options that repeats every two hours, and enable notification to Pub/Sub topic. Use Pub/Sub and Cloud Functions to send an email after three failed executions.
Your team has created multiple BigQuery curated datasets that contain anonymized industry benchmark data. You want to make these datasets readily discoverable and available for external partner companies to query from their own Google Cloud projects. You need a secure, scalable solution. What should you do?
APublish the datasets as listings within BigQuery sharing (Analytics Hub).
BExport the datasets to partner-specific Cloud Storage buckets.
CCreate authorized views for each dataset and grant access to each partner.
DGrant the roles/bigquery.dataViewer IAM role to the partner group email addresses on the datasets.
You administer a BigQuery dataset that uses a customer-managed encryption key (CMEK). You must share the dataset with a partner organization that lacks access to your CMEK. What should you do?
AProvide the partner organization a copy of your CMEKs to decrypt the data.
BExport the tables to parquet files to a Cloud Storage bucket and grant the storageinsights.viewer role on the bucket to the partner organization.
CCopy the tables you need to share to a dataset without CMEKs. Create an Analytics Hub listing for this dataset.
DCreate an authorized view that contains the CMEK to decrypt the data when accessed.
Your organization is modernizing its IT services and moving to Google Cloud. You must organize the data that will be stored in Cloud Storage and BigQuery. You need to implement a data mesh approach for sharing data among the sales, product design, and marketing departments. What should you do?
A
Create a project for storage of the data for each of your departments.2. Enable each department to create Cloud Storage buckets and BigQuery datasets.3. Create user groups for authorized readers for each bucket and dataset.4. Enable the IT team to administer the user groups to add or remove users as the departments’ request.
B
Create multiple projects for storage of the data for each of your departments’ applications.2. Enable each department to create Cloud Storage buckets and BigQuery datasets.3. Publish the data that each department shared in Analytics Hub.4. Enable all departments to discover and subscribe to the data they need in Analytics Hub.
C
Create a project for storage of the data for your organization.2. Create a central Cloud Storage bucket with three folders to store the files for each department.3. Create a central BigQuery dataset with tables prefixed with the department name.4. Give viewer rights for the storage project for the users of your departments.
D
Create multiple projects for storage of the data for each of your departments’ applications.2. Enable each department to create Cloud Storage buckets and BigQuery datasets.3. In Dataplex, map each department to a data lake and the Cloud Storage buckets, and map the BigQuery datasets to zones.4. Enable each department to own and share the data of their data lakes.
You are designing a data model in BigQuery to store retail transaction data. Your two largest tables, sales_transaction_header and sales_transaction_line, have a tightly coupled, immutable relationship. These tables are seldom changed after loading and are often joined in queries. You need to model the sales_transaction_header and sales_transaction_line tables to enhance the performance of data analytics queries. What should you do?
ACreate a sales_transaction table that holds the sales_transaction_header information as rows and the sales_transaction_line rows as nested and repeated fields.
BCreate a sales_transaction table that holds the sales_transaction_header and sales_transaction_line information as rows, duplicating the sales_transaction_header data for each line.
CCreate a sales_transaction table that stores the sales_transaction_header and sales_transaction_line data as a JSON data type.
DCreate separate sales_transaction_header and sales_transaction_line tables and, when querying, specify the sales_transaction_line first in the WHERE clause.
You must deploy extra dependencies to every node of a Cloud Dataproc cluster at startup by using an existing initialization action. Company security policies require Cloud Dataproc nodes to have no Internet access, so public initialization actions cannot retrieve resources. What should you do?
ADeploy the Cloud SQL Proxy on the Cloud Dataproc master
BUse an SSH tunnel to give the Cloud Dataproc cluster access to the Internet
CCopy all dependencies to a Cloud Storage bucket within your VPC security perimeter
DUse Resource Manager to add the service account used by the Cloud Dataproc cluster to the Network User role
Flowlogistic management has concluded that the existing Apache Kafka servers cannot support the data volume required for the real-time inventory-tracking system.
You must build a new system on Google Cloud Platform (GCP) to feed the proprietary tracking software. The system must ingest data from a range of global sources, process and query it in real time, and store the data reliably. Which combination of GCP products should you select?
ACloud Pub/Sub, Cloud Dataflow, and Cloud Storage
BCloud Pub/Sub, Cloud Dataflow, and Local SSD
CCloud Pub/Sub, Cloud SQL, and Cloud Storage
DCloud Load Balancing, Cloud Dataflow, and Cloud Storage
You have a BigQuery dataset called customers. All tables will be tagged using a Data Catalog tag template named gdpr. The template includes one mandatory Boolean field, has_sensitive_data.
All employees must be able to perform a simple search to locate tables in the dataset where has_sensitive_data is either true or false. However, only the Human Resources (HR) group must be able to view the data in tables where has_sensitive_data is true. You grant the all-employees group the bigquery.metadataViewer and bigquery.connectionUser roles on the dataset. You want to minimize configuration overhead. What should you do next?
ACreate the “gdpr” tag template with private visibility. Assign the bigquery.dataViewer role to the HR group on the tables that contain sensitive data.
BCreate the “gdpr” tag template with private visibility. Assign the datacatalog.tagTemplateViewer role on this tag to the all employees group, and assign the bigquery.dataViewer role to the HR group on the tables that contain sensitive data.
CCreate the “gdpr” tag template with public visibility. Assign the bigquery.dataViewer role to the HR group on the tables that contain sensitive data.
DCreate the “gdpr” tag template with public visibility. Assign the datacatalog.tagTemplateViewer role on this tag to the all employees group, and assign the bigquery.dataViewer role to the HR group on the tables that contain sensitive data.
You recently deployed several data-processing jobs in your Cloud Composer 2 environment. Some Apache Airflow tasks are failing. The monitoring dashboard shows increased total worker memory usage and worker pod evictions. You need to resolve these errors. What should you do?
Choose two
AIncrease the directed acyclic graph (DAG) file parsing interval.
BIncrease the Cloud Composer 2 environment size from medium to large.
CIncrease the maximum number of workers and reduce worker concurrency.
DIncrease the memory available to the Airflow workers.
EIncrease the memory available to the Airflow triggerer.
You run an IoT pipeline based on Apache Kafka that typically receives about 5000 messages per second. You want to use Google Cloud Platform to create an alert as soon as the 1-hour moving average falls below 4000 messages per second. What should you do?
AConsume the stream of data in Dataflow using Kafka IO. Set a sliding time window of 1 hour every 5 minutes. Compute the average when the window closes, and send an alert if the average is less than 4000 messages.
BConsume the stream of data in Dataflow using Kafka IO. Set a fixed time window of 1 hour. Compute the average when the window closes, and send an alert if the average is less than 4000 messages.
CUse Kafka Connect to link your Kafka message queue to Pub/Sub. Use a Dataflow template to write your messages from Pub/Sub to Bigtable. Use Cloud Scheduler to run a script every hour that counts the number of rows created in Bigtable in the last hour. If that number falls below 4000, send an alert.
DUse Kafka Connect to link your Kafka message queue to Pub/Sub. Use a Dataflow template to write your messages from Pub/Sub to BigQuery. Use Cloud Scheduler to run a script every five minutes that counts the number of rows created in BigQuery in the last hour. If that number falls below 4000, send an alert.
You need to migrate 1 PB of data from an on-premises data center to Google Cloud. The data-transfer portion of the migration must take only a few hours. You want to follow Google-recommended practices to enable this large data transfer over a secure connection. What should you do?
AEstablish a Cloud Interconnect connection between the on-premises data center and Google Cloud, and then use the Storage Transfer Service.
BUse a Transfer Appliance and have engineers manually encrypt, decrypt, and verify the data.
CEstablish a Cloud VPN connection, start gcloud compute scp jobs in parallel, and run checksums to verify the data.
DReduce the data into 3 TB batches, transfer the data using gsutil, and run checksums to verify the data.
You create a critical report for your large team in Google Data Studio 360. The report uses Google BigQuery as its data source. You observe that visualizations do not display data that is less than 1 hour old. What should you do?
ADisable caching by editing the report settings.
BDisable caching in BigQuery by editing table details.
CRefresh your browser tab showing the visualizations.
DClear your browser history for the past hour then reload the tab showing the virtualizations.
You are defining a data-governance strategy for a new BigQuery table containing medical and financial data. You need a scalable solution that lets clinical researchers access patient medical data without financial information, while allowing the accounting team access to only financial data with minimal patient identifiers. What should you do?
AImplement column-level security policies in BigQuery tables with IAM permissions.
BCreate separate tables for personally identifiable information (PII), financial data, and anonymized medical data. Use IAM permissions to control access to each table.
CImplement row-level security policies in BigQuery tables with IAM permissions.
DCreate separate datasets with authorized views exposing only approved data.
You are monitoring your organization’s data lake, which is hosted on BigQuery. The ingestion pipelines read data from Pub/Sub and write it into BigQuery tables. After deploying a new version of the ingestion pipelines, the daily stored data grew by 50%. Pub/Sub data volumes remained unchanged, and only some tables had their daily partition data size double. You need to investigate and resolve the cause of the data increase. What should you do?
A
Check for duplicate rows in the BigQuery tables that have the daily partition data size doubled.2. Schedule daily SQL jobs to deduplicate the affected tables.3. Share the deduplication script with the other operational teams to reuse if this occurs to other tables.
B
Check for code errors in the deployed pipelines.2. Check for multiple writing to pipeline BigQuery sink.3. Check for errors in Cloud Logging during the day of the release of the new pipelines.4. If no errors, restore the BigQuery tables to their content before the last release by using time travel.
C
Check for duplicate rows in the BigQuery tables that have the daily partition data size doubled.2. Check the BigQuery Audit logs to find job IDs.3. Use Cloud Monitoring to determine when the identified Dataflow jobs started and the pipeline code version.4. When more than one pipeline ingests data into a table, stop all versions except the latest one.
D
Roll back the last deployment.2. Restore the BigQuery tables to their content before the last release by using time travel.3. Restart the Dataflow jobs and replay the messages by seeking the subscription to the timestamp of the release.
You are developing a niche product in the image-recognition domain. Your team has created a model dominated by custom C++ TensorFlow ops that it implemented. These ops run within the main training loop and perform large matrix multiplications. Training a model currently can take several days. You want to reduce this time substantially while keeping costs low by using an accelerator on Google Cloud. What should you do?
AUse Cloud TPUs without any additional adjustment to your code.
BUse Cloud TPUs after implementing GPU kernel support for your customs ops.
CUse Cloud GPUs after implementing GPU kernel support for your customs ops.
DStay on CPUs, and increase the size of the cluster you're training your model on.
Community Discussion