Professional Cloud DevOps Engineer Practice Exam — Free Online
QuestionQ1
Optimizing performance and cost
Save question
You need to lower the cost of virtual machines (VMs) for your organization. After evaluating different options, you choose to use preemptible VM instances.
Which application is appropriate for preemptible VMs?
AA scalable in-memory caching system.
BThe organization's public-facing website.
CA distributed, eventually consistent NoSQL database cluster with sufficient quorum.
DA GPU-accelerated video rendering platform that retrieves and stores videos in a storage bucket.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Applying site reliability engineering practices
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Implementing observability practices and troubleshooting issues
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ4
Optimizing performance and cost
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ5
Building and implementing CI/CD pipelines, including continuous testing, for application, infrastructure, and machine learning workloads
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
Bootstrapping and maintaining a Google Cloud organizationBuilding and implementing CI/CD pipelines, including continuous testing, for application, infrastructure, and machine learning workloadsApplying site reliability engineering practicesImplementing observability practices and troubleshooting issuesOptimizing performance and cost
Your company follows Site Reliability Engineering principles. You are preparing a postmortem for an incident caused by a software change that severely impacted users. You want to prevent a severe incident from occurring again in the future. What should you do?
AIdentify engineers responsible for the incident and escalate to the senior management.
BEnsure that test cases that catch errors of this type are run successfully before new software releases.
CFollow up with the employees who reviewed the changes and prescribe practices they should follow in the future.
DDesign a policy that will require on-call teams to immediately call engineers and management to discuss a plan of action if an incident occurs.
You are designing a hosting architecture in Google Kubernetes Engine (GKE) for business-critical applications. The applications expose custom metrics for monitoring with Prometheus. You need to collect the application metrics for alerting and troubleshooting. You want to minimize manual effort and ongoing maintenance while following Google-recommended practices. What should you do?
AInstall Prometheus servers in the GKE clusters. Configure Prometheus to scrape and forward the custom metrics to the Cloud Monitoring API.
BInstall the OpenTelemetry collector in the GKE clusters. Configure it to collect and export the custom metrics to Cloud Monitoring.
CModify each application to use the Cloud Monitoring API to push the custom metrics.
DConfigure Google Cloud Managed Service for Prometheus collection in the GKE clusters to collect the custom metrics.
Your company runs services using Google Kubernetes Engine (GKE). The GKE clusters in the development environment run applications with verbose logging enabled. Developers inspect logs by using the kubectl logs command and do not use Cloud Logging. Applications do not have a defined uniform logging structure.
You need to minimize the costs associated with application logging while continuing to collect GKE operational logs. What should you do?
ARun the gcloud container clusters update --logging=SYSTEM command for the development cluster.
BRun the gcloud container clusters update --logging=WORKLOAD command for the development cluster.
CRun the gcloud logging sinks update _Default --disabled command in the project associated with the development environment.
DAdd the severity >= DEBUG resource.type = "k8s_container" exclusion filter to the _Default logging sink in the project associated with the development environment.
You are configuring a CI/CD pipeline natively in Google Cloud. You want builds in a pre-production Google Kubernetes Engine (GKE) environment to be automatically load-tested before promotion to the production GKE environment. You must ensure that only builds that pass this test are deployed to production. You want to follow Google-recommended practices. How should you configure this pipeline with Binary Authorization?
ACreate an attestation for the builds that pass the load test by requiring the lead quality assurance engineer to sign the attestation by using their personal private key.
BCreate an attestation for the builds that pass the load test by using a private key stored in Cloud Key Management Service (Cloud KMS) with a service account JSON key stored as a Kubernetes Secret.
CCreate an attestation for the builds that pass the load test by using a private key stored in Cloud Key Management Service (Cloud KMS) authenticated through Workload Identity.
DCreate an attestation for the builds that pass the load test by requiring the lead quality assurance engineer to sign the attestation by using a key stored in Cloud Key Management Service (Cloud KMS).
QuestionQ6
Optimizing performance and cost
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ7
Building and implementing CI/CD pipelines, including continuous testing, for application, infrastructure, and machine learning workloads
QuestionQ8
Bootstrapping and maintaining a Google Cloud organization
QuestionQ9
Optimizing performance and cost
QuestionQ10
Implementing observability practices and troubleshooting issues
QuestionQ11
Building and implementing CI/CD pipelines, including continuous testing, for application, infrastructure, and machine learning workloads
QuestionQ12
Building and implementing CI/CD pipelines, including continuous testing, for application, infrastructure, and machine learning workloads
QuestionQ13
Implementing observability practices and troubleshooting issues
QuestionQ14
Implementing observability practices and troubleshooting issues
QuestionQ15
Implementing observability practices and troubleshooting issues
QuestionQ16
Bootstrapping and maintaining a Google Cloud organization
QuestionQ17
Applying site reliability engineering practices
QuestionQ18
Bootstrapping and maintaining a Google Cloud organization
QuestionQ19
Optimizing performance and cost
QuestionQ20
Building and implementing CI/CD pipelines, including continuous testing, for application, infrastructure, and machine learning workloads
QuestionQ21
Implementing observability practices and troubleshooting issues
QuestionQ22
Implementing observability practices and troubleshooting issues
QuestionQ23
Implementing observability practices and troubleshooting issues
QuestionQ24
Applying site reliability engineering practices
QuestionQ25
Applying site reliability engineering practices
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
You support the backend for a mobile phone game running on a Google Kubernetes Engine (GKE) cluster. The application serves HTTP requests from users.
You need to implement a solution to reduce network costs. What should you do?
AConfigure the VPC as a Shared VPC Host project.
BConfigure your network services on the Standard Tier.
CConfigure your Kubernetes cluster as a Private Cluster.
DConfigure a Google Cloud HTTP Load Balancer as Ingress.
You need to enforce multiple constraint templates across your Google Kubernetes Engine (GKE) clusters. The constraints include policy parameters, such as restrictions on the Kubernetes API. You must ensure that the policy parameters are kept in a GitHub repository and are automatically applied when changes occur. What should you do?
ASet up a GitHub action to trigger Cloud Build when there is a parameter change. In Cloud Build, run a gcloud CLI command to apply the change.
BWhen there is a change in GitHub. use a web hook to send a request to Anthos Service Mesh, and apply the change.
CConfigure Anthos Config Management with the GitHub repository. When there is a change in the repository, use Anthos Config Management to apply the change.
DConfigure Config Connector with the GitHub repository. When there is a change in the repository, use Config Connector to apply the change.
Your organization is beginning to containerize with Google Cloud. You require a fully managed storage solution for container images and Helm charts. Identify a storage solution with native integration with existing Google Cloud services, including Google Kubernetes Engine (GKE), Cloud Run, VPC Service Controls, and Identity and Access Management (IAM). What should you do?
AUse Docker to configure a Cloud Storage driver pointed at the bucket owned by your organization.
BConfigure an open source container registry server to run in GKE with a restrictive role-based access control (RBAC) configuration.
CConfigure Artifact Registry as an OCI-based container registry for both Helm charts and container images.
DConfigure Container Registry as an OCI-based container registry for container images.
You work for a global organization and run a monolithic application on Compute Engine. You need to choose a machine type for the application that optimizes CPU utilization with the fewest steps. You want to use historical system metrics to determine the machine type for the application and follow Google-recommended practices. What should you do?
AUse the Recommender API and apply the suggested recommendations.
BCreate an Agent Policy to automatically install Ops Agent in all VMs.
CInstall the Ops Agent in a fleet of VMs by using the gcloud CLI.
DReview the Cloud Monitoring dashboard for the VM and choose the machine type with the lowest CPU utilization.
You are diagnosing an issue with an application running in a Google Kubernetes Engine (GKE) cluster that has Binary Authorization enabled. You need to run a temporary Pod for troubleshooting by using an unsigned utility container image from Artifact Registry. When you try to apply the Pod configuration from a YAML file, the Binary Authorization policy blocks the deployment. You must use the most secure and auditable solution to run the Pod. What should you do?
AChange enforcementMode in the Binary Authorization policy to ALWAYS_ALLOW.
BAdd the imaqe-policy.k8s.io/break-glass label to the Pod configuration.
CTemporarily disable Binary Authorization on the GKE cluster.
DAdd the container image to the admissionWhitelistPatterns node in the Binary Authorization policy.
You use Terraform to manage an application deployed in a Google Cloud environment. The application runs on instances deployed by a managed instance group. The Terraform code is deployed through a CI/CD pipeline. When you change the machine type on the instance template used by the managed instance group, the pipeline fails during the terraform apply stage with the following error message:
You need to update the instance template while minimizing disruption to the application and the number of pipeline runs.
What should you do?
ADelete the managed instance group, and recreate it after updating the instance template.
BAdd a new instance template, update the managed instance group to use the new instance template, and delete the old instance template.
CRemove the managed instance group from the Terraform state file, update the instance template, and reimport the managed instance group.
DSet the create_before_destroy meta-argument to true in the lifecycle block on the instance template.
You must build a CI/CD pipeline for a containerized application in Google Cloud. Your development team uses a central Git repository for trunk-based development. You want the pipeline to run all tests for any new application versions to improve quality. What should you do?
A
Install a Git hook to require developers to run unit tests before pushing the code to a central repository.2. Trigger Cloud Build to build the application container. Deploy the application container to a testing environment, and run integration tests.3. If the integration tests are successful, deploy the application container to your production environment, and run acceptance tests.
B
Install a Git hook to require developers to run unit tests before pushing the code to a central repository. If all tests are successful, build a container.2. Trigger Cloud Build to deploy the application container to a testing environment, and run integration tests and acceptance tests.3. If all tests are successful, tag the code as production ready. Trigger Cloud Build to build and deploy the application container to the production environment.
C
Trigger Cloud Build to build the application container, and run unit tests with the container.2. If unit tests are successful, deploy the application container to a testing environment, and run integration tests.3. If the integration tests are successful, the pipeline deploys the application container to the production environment. After that, run acceptance tests.
D
Trigger Cloud Build to run unit tests when the code is pushed. If all unit tests are successful, build and push the application container to a central registry.2. Trigger Cloud Build to deploy the container to a testing environment, and run integration tests and acceptance tests.3. If all tests are successful, the pipeline deploys the application to the production environment and runs smoke tests
Your team is getting ready to launch a new API on Cloud Run. The API uses an OpenTelemetry agent to send distributed tracing data to Cloud Trace to monitor how long each request takes. The team has observed inconsistent trace collection. You need to fix the issue. What should you do?
AUse an HTTP health check.
BConfigure CPU to be always-allocated.
CIncrease the CPU limit in Cloud Run from 2 to 4.
DConfigure CPU to be allocated only during request processing.
Your company’s security team requires read-only access to Data Access audit logs in the _Required bucket. You want to grant the required permissions to the security team according to the principle of least privilege and Google-recommended practices. What should you do?
AAssign the roles/logging.viewer role to each member of the security team.
BAssign the roles/logging.viewer role to a group with all the security team members.
CAssign the roles/logging.privateLogViewer role to each member of the security team.
DAssign the roles/logging.privateLogViewer role to a group with all the security team members.
You are conducting an experiment to determine whether users like a new feature in a web application. Soon after deploying the feature as a canary release, you see a spike in 500 errors returned to users, and monitoring indicates higher latency. You want to minimize the negative effect on users as quickly as possible. What should you do first?
ARoll back the experimental canary release.
BStart monitoring latency, traffic, errors, and saturation.
CRecord data for the postmortem document of the incident.
DTrace the origin of 500 errors and the root cause of increased latency.
You manage a Google Cloud environment for 20 different business units, with 50 production projects and 50 development projects located directly under the organization node. This flat hierarchy makes it hard to apply security policies consistently to all production projects and to track the combined costs of the production and development environments separately. You need to reorganize the resource hierarchy to address these issues. What should you do?
ACreate folders for the production and development environments, and move the projects into these folders.
BCreate a folder for each business unit, and move the corresponding projects into these folders.
CApply labels for each environment to each project to identify the environment.
DCreate a common services project for each business unit.
You are deploying an application that requires access to sensitive information. You need to make sure this information is encrypted and that the risk of exposure is minimized in the event of a breach. What should you do?
AStore the encryption keys in Cloud Key Management Service (KMS) and rotate the keys frequently
BInject the secret at the time of instance creation via an encrypted configuration management system.
CIntegrate the application with a Single sign-on (SSO) system and do not expose secrets to the application.
DLeverage a continuous build pipeline that produces multiple versions of the secret for each instance of the application.
You are developing an application that runs on Cloud Run. The application must access a third-party API using an API key. You need to identify a secure method to store and use the API key in the application while following Google-recommended practices. What should you do?
ASave the API key in Secret Manager as a secret. Reference the secret as an environment variable in the Cloud Run application.
BSave the API key in Secret Manager as a secret key. Mount the secret key under the /sys/api_key directory, and decrypt the key in the Cloud Run application.
CSave the API key in Cloud Key Management Service (Cloud KMS) as a key. Reference the key as an environment variable in the Cloud Run application.
DEncrypt the API key by using Cloud Key Management Service (Cloud KMS), and pass the key to Cloud Run as an environment variable. Decrypt and use the key in Cloud Run.
A team is developing a service that performs compute-intensive processing on batches of data. Data is processed more quickly according to the machine's CPU speed and CPU count. These data batches vary in size and can arrive at any time from multiple third-party sources. You must ensure that third parties can upload their data securely. You want to minimize costs while ensuring the data is processed as quickly as possible. What should you do?
AProvide a secure file transfer protocol (SFTP) server on a Compute Engine instance so that third parties can upload batches of data, and provide appropriate credentials to the server.Create a Cloud Function with a google.storage.object.finalize Cloud Storage trigger. Write code so that the function can scale up a Compute Engine autoscaling managed instance groupUse an image pre-loaded with the data processing software that terminates the instances when processing completes.
BProvide a Cloud Storage bucket so that third parties can upload batches of data, and provide appropriate Identity and Access Management (IAM) access to the bucket.Use a standard Google Kubernetes Engine (GKE) cluster and maintain two services: one that processes the batches of data, and one that monitors Cloud Storage for new batches of data.Stop the processing service when there are no batches of data to process.
CProvide a Cloud Storage bucket so that third parties can upload batches of data, and provide appropriate Identity and Access Management (IAM) access to the bucket.Create a Cloud Function with a google.storage.object.finalize Cloud Storage trigger. Write code so that the function can scale up a Compute Engine autoscaling managed instance group.Use an image pre-loaded with the data processing software that terminates the instances when processing completes.
DProvide a Cloud Storage bucket so that third parties can upload batches of data, and provide appropriate Identity and Access Management (IAM) access to the bucket.Use Cloud Monitoring to detect new batches of data in the bucket and trigger a Cloud Function that processes the data.Set a Cloud Function to use the largest CPU possible to minimize the runtime of the processing.
You are configuring a CI pipeline in Cloud Build. When you test the pipeline, the following cloudbuild.yaml definition results in 5 minutes for each of the foo and bar steps.
The foo and bar steps are independent of one another. The baz step requires both the foo and bar steps to complete before it starts. You want to use parallelism to reduce build times. What should you do?
AModify the build script to add -options:machineType: 'E2_HIGHCPU_8'
BModify the build script to add -options:machineType: 'E2_HIGHCPU_32'
C
D
You manage an application that exposes an HTTP endpoint without a load balancer. HTTP response latency is important to the user experience. You need to understand the HTTP latencies experienced by all of your users. You use Stackdriver Monitoring. What should you do?
Aג€¢ In your application, create a metric with a metricKind set to DELTA and a valueType set to DOUBLE. ג€¢ In Stackdriver's Metrics Explorer, use a Stacked Bar graph to visualize the metric.
Bג€¢ In your application, create a metric with a metricKind set to CUMULATIVE and a valueType set to DOUBLE. ג€¢ In Stackdriver's Metrics Explorer, use a Line graph to visualize the metric.
Cג€¢ In your application, create a metric with a metricKind set to GAUGE and a valueType set to DISTRIBUTION. ג€¢ In Stackdriver's Metrics Explorer, use a Heatmap graph to visualize the metric.
Dג€¢ In your application, create a metric with a metricKind set to METRIC_KIND_UNSPECIFIED and a valueType set to INT64. ג€¢ In Stackdriver's Metrics Explorer, use a Stacked Area graph to visualize the metric.
You are running an application on Compute Engine and collecting its logs through Stackdriver. You discover that some personally identifiable information (PII) is leaking into certain log entry fields. You want to prevent these fields from being written into new log entries as quickly as possible.
What should you do?
AUse the filter-record-transformer Fluentd filter plugin to remove the fields from the log entries in flight.
BUse the fluent-plugin-record-reformer Fluentd output plugin to remove the fields from the log entries in flight.
CWait for the application developers to patch the application, and then verify that the log entries are no longer exposing PII.
DStage log entries to Cloud Storage, and then trigger a Cloud Function to remove the fields and write the entries to Stackdriver via the Stackdriver Logging API.
You need to establish SLOs for a high-traffic web application. Customers are currently satisfied with the application's performance and availability. Current measurements over a 28-day window show a 90th-percentile latency of 160 ms and a 95th-percentile latency of 300 ms. What latency SLO should you publish?
A90th percentile - 150 ms95th percentile - 290 ms
B90th percentile - 160 ms95th percentile - 300 ms
C90th percentile - 190 ms95th percentile - 330 ms
D90th percentile - 300 ms95th percentile - 450 ms
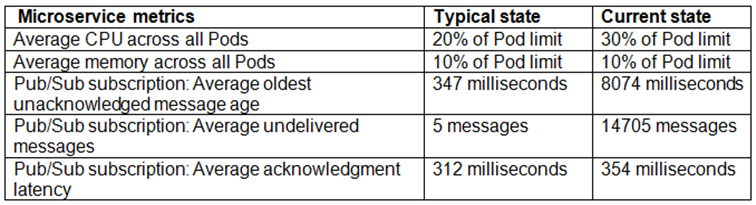
You are the on-call Site Reliability Engineer for a microservice deployed in a Google Kubernetes Engine (GKE) Autopilot cluster. Your company operates an online store that publishes order messages to Pub/Sub, and a microservice consumes those messages and updates stock information in the warehousing system. A sales event has increased orders, and stock information is not being updated fast enough. Consequently, many orders are being accepted for products that are out of stock. You review the microservice metrics and compare them with typical levels:
You must ensure the warehouse system accurately reflects product inventory when orders are placed while minimizing customer impact. What should you do?
ADecrease the acknowledgment deadline on the subscription.
BAdd a virtual queue to the online store that allows typical traffic levels.
CIncrease the number of Pod replicas.
DIncrease the Pod CPU and memory limits.
Your CTO has asked that you implement an internal postmortem policy for every incident. You want to define the characteristics of a good postmortem so that the policy succeeds at your company. What should you do?
Choose two
AEnsure that all postmortems include what caused the incident, identify the person or team responsible for causing the incident, and how to prevent a future occurrence of the incident.
BEnsure that all postmortems include what caused the incident, how the incident could have been worse, and how to prevent a future occurrence of the incident.
CEnsure that all postmortems include the severity of the incident, how to prevent a future occurrence of the incident, and what caused the incident without naming internal system components.
DEnsure that all postmortems include how the incident was resolved and what caused the incident without naming customer information.
EEnsure that all postmortems include all incident participants in postmortem authoring and share postmortems as widely as possible.




Community Discussion