Professional Cloud Developer Practice Exam — Google Certification
QuestionQ1
Deploying applications
Save question
An application is deployed in a Google Kubernetes Engine (GKE) cluster. You want to expose the application publicly behind a Cloud Load Balancing HTTP(S) load balancer.
What should you do?
AConfigure a GKE Ingress resource.
BConfigure a GKE Service resource.
CConfigure a GKE Ingress resource with type: LoadBalancer.
DConfigure a GKE Service resource with type: LoadBalancer.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Integrating applications with Google Cloud services
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Integrating applications with Google Cloud services
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ4
Deploying applications
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ5
Integrating applications with Google Cloud services
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
Designing scalable, available, and reliable cloud-native applicationsBuilding and testing applicationsDeploying applicationsIntegrating applications with Google Cloud services
You are building an application component to collect user-behavior data and stream it into BigQuery. You plan to use the BigQuery Storage Write API. You must ensure that data arriving in BigQuery contains no duplicates. You want to achieve this by using the simplest operational approach. What should you do?
ACreate a write stream in the default type.
BCreate a write stream in the committed type.
CConfigure a Kafka cluster. Use a primary universally unique identifier (UUID) for duplicate messages.
DConfigure a Pub/Sub topic. Use Cloud Functions to subscribe to the topic and remove any duplicates.
Your organization has users and groups configured in an external identity provider (IdP). You want to use that same external IdP to let all employees access the Google Cloud console. You also want to personalize sign-in by showing each user's name and photo when they access the Google Cloud console. What should you do?
AConfigure workforce identity federation with the external IdP, and set up attribute mapping.
BConfigure a service account for each individual by using the user name and photo, and grant permissions for each user to impersonate their respective service accounts.
CConfigure workload identity federation to get the external IdP tokens, and use these tokens to sign in to the Google Cloud console.
DCreate a Google group that includes organization email IDs for all users. Ask users to use the same name, work email ID, and password to register and sign in.
You work for an ecommerce company. The company is migrating multiple applications to Google Cloud, and you are helping migrate one of them. The application is currently deployed on a VM with no OS dependencies. You created a Dockerfile and used it to upload a new image to Artifact Registry. You want to minimize infrastructure and operational complexity. What should you do?
ADeploy the image to Cloud Run.
BDeploy the image to a GKE Autopilot cluster.
CDeploy the image to a GKE Standard cluster.
DDeploy the image to a Compute Engine instance.
To store application state and fulfill HipLocal’s stated business requirements, which database service should it migrate to?
ACloud Spanner
BCloud Datastore
CCloud Memorystore as a cache
DSeparate Cloud SQL clusters for each region
QuestionQ6
Designing scalable, available, and reliable cloud-native applications
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ7
Designing scalable, available, and reliable cloud-native applications
QuestionQ8
Designing scalable, available, and reliable cloud-native applications
QuestionQ9
Integrating applications with Google Cloud services
QuestionQ10
Designing scalable, available, and reliable cloud-native applications
QuestionQ11
Integrating applications with Google Cloud services
QuestionQ12
Integrating applications with Google Cloud services
QuestionQ13
Deploying applications
QuestionQ14
Building and testing applications
QuestionQ15
Designing scalable, available, and reliable cloud-native applications
QuestionQ16
Deploying applications
QuestionQ17
Integrating applications with Google Cloud services
QuestionQ18
Integrating applications with Google Cloud services
QuestionQ19
Integrating applications with Google Cloud services
QuestionQ20
Integrating applications with Google Cloud services
QuestionQ21
Integrating applications with Google Cloud services
QuestionQ22
Deploying applications
QuestionQ23
Integrating applications with Google Cloud services
QuestionQ24
Integrating applications with Google Cloud services
QuestionQ25
Building and testing applications
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
You are designing a microservices application on GKE that will expose a public API to users. Users will access the application using OAuth 2.0, and illegitimate requests must receive a 403 response code. The API must be resilient to distributed denial-of-service (DDoS) attacks and critical security risks such as SQL injection (SQL) and cross-site scripting (XSS).
You want to design the application's architecture according to Google-recommended practices. What should you do?
AInstall Service Mesh in your GKE cluster. Configure Service Mesh user authentication to integrate the service hosted on GKE by using an OpenID Connect-compliant identity provider. Expose the application externally by using an Istio Ingress Gateway. Use VPC firewall rules to restrict Ingress traffic to the Ingress gateway.
BRun an Apache HTTP server on Cloud Run to expose a service with a public IP address. Configure the Apache HTTP server as a reverse proxy to only forward valid requests to the API hosted on GKE.
CUse an external Application Load Balancer with Cloud Armor. Integrate Cloud Armor with reCAPTCHA Enterprise. Configure the load balancer to forward traffic to the application hosted on GKE.
DUse an external Application Load Balancer with Cloud Armor, and configure the load balancer to forward requests to Apigee to check the validity of the API requests. Configure GKE as the application's backend.
You are building an ecommerce application that stores customer, order, and inventory data in relational tables within Cloud Spanner. A recent load test shows that Spanner performance is not scaling linearly as expected. Which of the following is causing this?
AThe use of 64-bit numeric types for 32-bit numbers.
BThe use of the STRING data type for arbitrary-precision values.
CThe use of Version 1 UUIDs as primary keys that increase monotonically.
DThe use of LIKE instead of STARTS_WITH keyword for parameterized SQL queries.
You configured your Compute Engine instance group to autoscale based on overall CPU utilization. However, your application's response latency rises sharply before the cluster has completed adding instances. You want to deliver a more consistent latency experience to end users by modifying the instance group autoscaler configuration.
Which two configuration changes should you make?
Choose two
AAdd the label ג€AUTOSCALEג€ to the instance group template.
BDecrease the cool-down period for instances added to the group.
CIncrease the target CPU usage for the instance group autoscaler.
DDecrease the target CPU usage for the instance group autoscaler.
ERemove the health-check for individual VMs in the instance group.
You are building a mobile application that lets users create and manage to-do lists. Your application must meet the following requirements:
Store and synchronize data across different mobile devices.
Support offline access.
Deliver real-time updates on every user's device.
You need to implement a database solution while minimizing operational effort. Which approach should you use?
ACreate a Cloud SQL for MySQL instance. Implement a data model to store to-do list information. Create indexes for the most heavily and frequently used queries.
BCreate a Bigtable instance. Design a database schema to avoid hotspots when writing data. Use a Bigtable change stream to capture data changes.
CUse Firestore as the database. Configure Firestore offline persistence to cache a copy of the Firestore data. Listen to document changes to update applications whenever there are document changes.
DImplement a SQLite database on each user's device. Use a scheduled job to synchronize each device database with a copy stored in Cloud Storage.
You are designing a resource-sharing policy for applications used by different teams in a Google Kubernetes Engine cluster. You must ensure that every application can obtain the resources required to run. What should you do?
Choose two
ASpecify the resource limits and requests in the object specifications.
BCreate a namespace for each team, and attach resource quotas to each namespace.
CCreate a LimitRange to specify the default compute resource requirements for each namespace.
DCreate a Kubernetes service account (KSA) for each application, and assign each KSA to the namespace.
EUse the Anthos Policy Controller to enforce label annotations on all namespaces. Use taints and tolerations to allow resource sharing for namespaces.
Your application stores customer content in a Cloud Storage bucket, and every object is encrypted with that customer's encryption key. Each Cloud Storage object key is entered into your application by the customer. You find that the application receives an HTTP 4xx error while reading an object from Cloud Storage. What could cause this error?
AYou attempted the read operation on the object with the customer's base64-encoded key.
BYou attempted the read operation without the base64-encoded SHA256 hash of the encryption key.
CYou entered the same encryption algorithm specified by the customer when attempting the read operation.
DYou attempted the read operation on the object with the base64-encoded SHA256 hash of the customer's key.
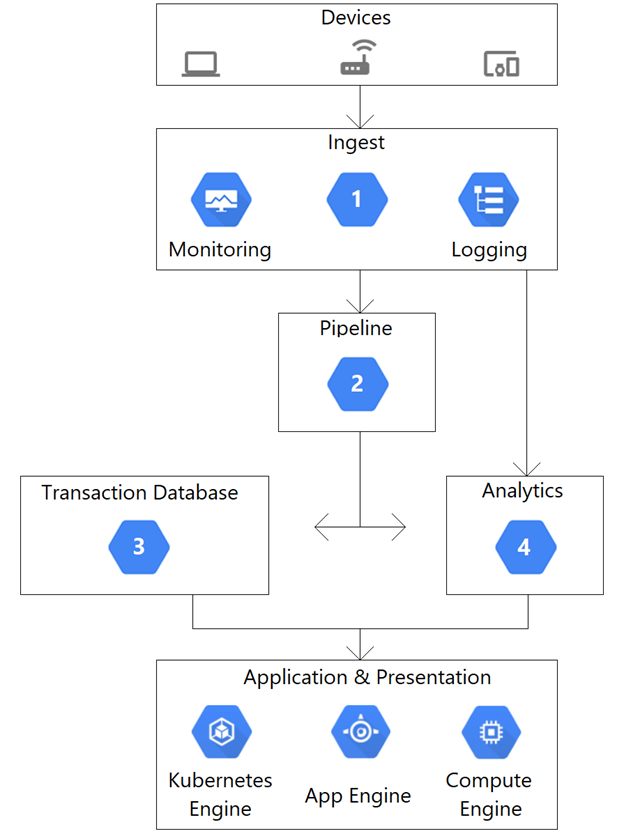
This architecture diagram shows a system streaming data from thousands of devices. You want to ingest the data into a pipeline, store it, and analyze it by using SQL statements. Which Google Cloud services should be used for steps 1, 2, 3, and 4?
A
App Engine2. Pub/Sub3. BigQuery4. Firestore
B
Dataflow2. Pub/Sub3. Firestore4. BigQuery
C
Pub/Sub2. Dataflow3. BigQuery4. Firestore
D
Pub/Sub2. Dataflow3. Firestore4. BigQuery
You are deploying a microservices application to Google Kubernetes Engine (GKE). The application will receive daily updates. You anticipate deploying a large number of distinct containers that will run on the Linux operating system (OS). You want to be alerted to any known OS vulnerabilities in the new containers. You want to follow Google-recommended best practices. What should you do?
AUse the gcloud CLI to call Container Analysis to scan new container images. Review the vulnerability results before each deployment.
BEnable Container Analysis, and upload new container images to Artifact Registry. Review the vulnerability results before each deployment.
CEnable Container Analysis, and upload new container images to Artifact Registry. Review the critical vulnerability results before each deployment.
DUse the Container Analysis REST API to call Container Analysis to scan new container images. Review the vulnerability results before each deployment.
A company stores its source code in a Cloud Source Repositories repository. The company wants to build and test its code on every source-code commit to the repository and requires a managed solution with minimal operational overhead.
Which method should it use?
AUse Cloud Build with a trigger configured for each source code commit.
BUse Jenkins deployed via the Google Cloud Platform Marketplace, configured to watch for source code commits.
CUse a Compute Engine virtual machine instance with an open source continuous integration tool, configured to watch for source code commits.
DUse a source code commit trigger to push a message to a Cloud Pub/Sub topic that triggers an App Engine service to build the source code.
You want to re-architect a monolithic application so it follows a microservices model. You want to do this efficiently while minimizing the business impact of the change.
Which approach should you use?
ADeploy the application to Compute Engine and turn on autoscaling.
BReplace the application's features with appropriate microservices in phases.
CRefactor the monolithic application with appropriate microservices in a single effort and deploy it.
DBuild a new application with the appropriate microservices separate from the monolith and replace it when it is complete.
Your company has deployed a new API to the App Engine Standard environment. During testing, the API is not functioning as expected. You want to monitor the application over time to diagnose the issue within the application code, without redeploying the application.
Which tool should you use?
AStackdriver Trace
BStackdriver Monitoring
CStackdriver Debug Snapshots
DStackdriver Debug Logpoints
You are attempting to connect to your Google Kubernetes Engine (GKE) cluster with kubectl from Cloud Shell. You deployed the GKE cluster with a public endpoint. From Cloud Shell, you run this command:
You observe that kubectl commands time out without producing an error message. What is the most likely cause?
AYour user account does not have privileges to interact with the cluster using kubectl.
BYour Cloud Shell external IP address is not part of the authorized networks of the cluster.
CThe Cloud Shell is not part of the same VPC as the GKE cluster.
DA VPC firewall is blocking access to the cluster’s endpoint.
You are designing a Node.js-based mobile news-feed application that stores data on Google Cloud. You need to choose the application's database. You want the database to provide out-of-the-box zonal resiliency, low-latency responses, ACID compliance, an optional middle tier, semi-structured data storage, and client libraries that tolerate network partitions and support offline mode. What should you do?
AConfigure Firestore and use the Firestore client library in the app.
BConfigure Bigtable and use the Bigtable client in the app.
CConfigure Cloud SQL and use the Google Client Library for Cloud SQL in the app.
DConfigure BigQuery and use the BigQuery REST API in the app.
You are using the latest stable release of Python 3 to build an API that stores data in a Cloud SQL database. You must perform CRUD operations on the production database securely and reliably with minimal effort. What should you do?
A
Use Cloud Composer to manage the connection to the Cloud SQL database from your Python application.2. Grant an IAM role to the service account that includes the composer.worker permission.
B
Use the Cloud SQL API to connect to the Cloud SQL database from your Python application.2. Grant an IAM role to the service account that includes the cloudsql.instances.login permission.
C
Use the Cloud SQL connector library for Python to connect to the Cloud SQL database through a Cloud SQL Auth Proxy.2. Grant an IAM role to the service account that includes the cloudsql.instances.connect permission.
D
Use the Cloud SQL emulator to connect to the Cloud SQL database from Cloud Shell2. Grant an IAM role to the user that includes the cloudsql.instances.login permission.
You are building a microservice-based application that will run on Google Kubernetes Engine (GKE). Some services must access different Google Cloud APIs. How should you configure authentication for these services in the cluster according to Google-recommended best practices?
Choose two
AUse the service account attached to the GKE node.
BEnable Workload Identity in the cluster via the gcloud command-line tool.
CAccess the Google service account keys from a secret management service.
DStore the Google service account keys in a central secret management service.
EUse gcloud to bind the Kubernetes service account and the Google service account using roles/iam.workloadIdentity.
You operate a system that runs on stateless Compute Engine VMs and Cloud Run instances. Cloud Run is connected to a VPC, and its ingress setting is configured as Internal. You want to schedule tasks on Cloud Run. You create a service account and grant it the roles/run.invoker Identity and Access Management (IAM) role. When you create a schedule and test it, Cloud Logging returns a 403 Permission Denied error. What should you do?
AGrant the service account the roles/run.developer IAM role.
BConfigure a cron job on the Compute Engine VMs to trigger Cloud Run on schedule.
CChange the Cloud Run ingress setting to 'Internal and Cloud Load Balancing.'
DUse Cloud Scheduler with Pub/Sub to invoke Cloud Run.
Your application team is building an ecommerce application. The team has created new functionality that depends on a third-party service. That third-party service will be deployed in several days, but its reliability has not been confirmed. You need to select a deployment strategy for the ecommerce application that avoids disruption and can be rolled back quickly if problems are found. What should you do?
ADeploy the new functionality by using an A/B deployment strategy.
BDeploy the new functionality to all users by using a blue/green deployment strategy.
CUse a feature flag to enable the new functionality to users on demand. Gradually enable the new functionality to more users.
DGradually roll out the new functionality by using a rolling updates deployment strategy. Start with a small subset of users and increase the number of users over time.
You must redesign audit-event ingestion from your authentication service so it can accommodate a substantial traffic increase. Currently, the audit service and authentication system run on the same Compute Engine virtual machine. You plan to use these Google Cloud tools in the new architecture:
Multiple Compute Engine machines, each running an authentication-service instance
Multiple Compute Engine machines, each running an audit-service instance
Pub/Sub to send events from the authentication services
How should the topics and subscriptions be configured to ensure the system handles a high message volume and scales efficiently?
ACreate one Pub/Sub topic. Create one pull subscription to allow the audit services to share the messages.
BCreate one Pub/Sub topic. Create one pull subscription per audit service instance to allow the services to share the messages.
CCreate one Pub/Sub topic. Create one push subscription with the endpoint pointing to a load balancer in front of the audit services.
DCreate one Pub/Sub topic per authentication service. Create one pull subscription per topic to be used by one audit service.
ECreate one Pub/Sub topic per authentication service. Create one push subscription per topic, with the endpoint pointing to one audit service.
Your company’s development teams want to use Cloud Build in their projects to build and push Docker images to Container Registry. The operations team requires that all Docker images be published to a centralized, securely managed Docker registry operated by the operations team.
What should you do?
AUse Container Registry to create a registry in each development team's project. Configure the Cloud Build build to push the Docker image to the project's registry. Grant the operations team access to each development team's registry.
BCreate a separate project for the operations team that has Container Registry configured. Assign appropriate permissions to the Cloud Build service account in each developer team's project to allow access to the operation team's registry.
CCreate a separate project for the operations team that has Container Registry configured. Create a Service Account for each development team and assign the appropriate permissions to allow it access to the operations team's registry. Store the service account key file in the source code repository and use it to authenticate against the operations team's registry.
DCreate a separate project for the operations team that has the open source Docker Registry deployed on a Compute Engine virtual machine instance. Create a username and password for each development team. Store the username and password in the source code repository and use it to authenticate against the operations team's Docker registry.
Your production application has recently experienced reliability problems, and you are uncertain how it will behave if an unexpected failure occurs. You want to evaluate the application's resilience. What should you do?
AWrite end-to-end tests to determine how different microservices interact. Validate that all tests pass.
BPerform chaos engineering by intentionally introducing failures into the system. Observe how the application behaves, and ensure that it is able to recover from a failure.
CTest individual units of code for a critical portion of the application's code. Ensure that unit tests are part of the Cloud Build pipeline.
DPerform load testing of the application, and use JMeter for the critical endpoints of the application. Ensure that the application performs as expected under a heavy load.

Community Discussion