Certified Machine Learning Professional Databricks Practice Exam
QuestionQ1
Drift Detection and Lakehouse Monitoring
Save question
A Machine Learning Engineer must implement a simple solution, using as little code as possible, to monitor a regression model and ensure that the R2 score does not exceed a specified threshold. If that threshold is exceeded, the solution must send an email to a distribution list.
Which proposed solution satisfies these requirements?
AConfigure Lakehouse Monitoring using the Inference profile type. Create a SQL Alert that runs on a schedule and evaluates if the R2 score in the profile table exceeds the threshold. If so, the Alert should send an email to the configured email notification destination.
BConfigure Lakehouse Monitoring using the Inference profile type. Create a SQL Query that runs on a schedule and evaluates if the R2 score in the profile table exceeds the threshold. If so, the Alert should send an email to the configured email notification destination.
CConfigure Lakehouse Monitoring using the Inference profile type. Create a Workflow that runs on a schedule and executes a SQL query that evaluates the R2 score in the profile table. Use Workflow If/Else condition to execute a Notebook Task that sends the email if the R2 score threshold is exceeded.
DCreate a Workflow that runs on a schedule. The Workflow executes a SQL Query that calculates the R2 score. Use Workflow If/Else condition to execute a Notebook Task that sends the email if the R2 score threshold is exceeded.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Environment Architectures
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Advanced MLflow Usage
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ5
Model Lifecycle Management
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ6
Using Spark ML
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
Using Spark MLScaling and TuningAdvanced MLflow UsageAdvanced Feature Store ConceptsModel Lifecycle ManagementValidation TestingEnvironment ArchitecturesAutomated RetrainingDrift Detection and Lakehouse MonitoringDeployment StrategiesCustom Model Serving
A Machine Learning Engineer is configuring a cluster for a deep learning training run, with several settings to select. The cluster will be reused by other engineers on the team, and their datasets range in size from hundreds of MBs to hundreds of GBs. They must select a configuration that supports performant, stable deep learning training without excessive cost.
Which configuration accomplishes this?
AUsing ML Runtime, use a moderate sized GPU VM for the driver and a variable number of memory optimized CPU VMs for the workers with autoscale enabled
BUsing ML Runtime, use a large single node, GPU-enabled VM with auto termination set to 20 minutes to reduce costs
CUsing ML Runtime, use a moderately sized CPU VM for the driver and a variable number of GPU enabled VMs for the workers with autoscale enabled
DUsing Databricks Runtime, use a moderately sized CPU VM for the driver and a variable number of GPU enabled VMs for the workers with autoscale enabled
A machine learning engineer is migrating a machine learning pipeline to Databricks Machine Learning. The pipeline must automatically refresh its model whenever it runs. The project is attached to the existing model_name model in the MLflow Model Registry.
They use the following code block as part of their solution:
Which statement explains the effect of the registered_model_name=model_name parameter and argument, given that model_name already exists in the MLflow Model Registry?
AIt identifies the name of the logged model in the MLflow Experiment.
BIt avoids the need to specify the model name in the subsequent required call to mflow.register_model.
CIt registers the new version of the model_name model in the MLflow Model Registry.
DIt registers a new model called model_name in the MLflow Model Registry.
Which of the following lists all model stages available in the MLflow Model Registry?
ADevelopment, Staging, Production
BNone, Staging, Production
CStaging, Production, Archived
DNone, Staging, Production, Archived
EDevelopment, Staging, Production, Archived
A Data Scientist is creating a pipeline to train multiple machine-learning models. They have a dataframe containing a group column, many feature columns, and one label column.
Their requirements are:
An independent model for each group
Direct use of the data in the columns without transformation
Flexibility to select from many different model types
Efficient distributed-computing capabilities
They are deciding between the pyspark.ml library and pandas UDFs through groupby().ApplyInPandas() to train the models. They choose the groupBy().ApplyInPandas() approach.
What is a valid reason for this choice?
AgroupBy().ApplyInPandas() can encapsulate training models using a variety of python packages such as sklearn and PyTorch.
BA function used with groupBy().ApplyInPandas() can return any python object, including custom model objects.
Cpyspark.ml models can have features defined as multiple input columns from a dataframe without transformation.
DThe groupby().ApplyInPandas()strategy can handle arbitrarily large data in each group for the same worker node size due to its distribution strategy.
QuestionQ7
Advanced MLflow Usage
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ8
Validation Testing
QuestionQ9
Custom Model Serving
QuestionQ10
Validation Testing
QuestionQ11
Using Spark ML
QuestionQ12
Deployment Strategies
QuestionQ13
Custom Model Serving
QuestionQ14
Drift Detection and Lakehouse Monitoring
QuestionQ15
Advanced MLflow Usage
QuestionQ16
Drift Detection and Lakehouse Monitoring
QuestionQ17
Drift Detection and Lakehouse Monitoring
QuestionQ18
Advanced MLflow Usage
QuestionQ19
Advanced MLflow Usage
QuestionQ20
Advanced Feature Store Concepts
QuestionQ21
Scaling and Tuning
QuestionQ22
Custom Model Serving
QuestionQ23
Advanced MLflow Usage
QuestionQ24
Scaling and Tuning
QuestionQ25
Using Spark ML
QuestionQ26
Deployment Strategies
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
A data scientist has developed a model and calculated the model's RMSE on the test set. They assigned this value to the rmse variable. They now want to manually log the RMSE value in the MLflow run.
They write the following incomplete code block:
Which of the following lines of code can fill the blank so that the code block successfully completes the task?
Alog_artifact
Blog_model
Clog_metric
Dlog_param
EThere is no way to store values like this.
A Machine Learning Engineer has defined a model with Python notebooks in a Databricks Git folder and wants to add unit tests to their CI/CD workflow. They need a workflow that is highly automated and straightforward to maintain.
Which strategy should they use?
AUse the %sh and -m shell commands to call the unit test module inside the notebook.
BUse the web terminal to run unit tests in the source code before each commit.
CUse Databricks GitHub Actions to run notebook tests before each commit.
DUse the %run magic command to call the unit test module from another notebook.
A Data Scientist created a sales-forecasting sales-prediction model. The model is deployed to a model-serving endpoint with a schema. They need to call this model from Python and would prefer an SDK function to submit the request.
Which method meets these requirements?
AImport the MLflow Deployments class and use the predict method and provide the endpoint and input parameters.
BUse the built in ai_query function and provide the endpoints and request parameters.
CImport the MLflow Deployments class and use the ai_query method and provide the endpoints and request parameters.
DMake an API request to the MODEL_VERSION_URI and provide the dataframe_split as the request parameter.
A team is developing a machine learning pipeline that includes feature engineering, model training, model evaluation, and model deployment. During the last year, the project has grown substantially, with multiple contributors working on it. They currently test their pipelines and functions manually, but they want to establish an MLOps process and organize their unit tests.
Which approach should they use to organize functions and unit tests?
AOrganize functions and unit tests together in multiple notebooks, grouping them by feature or component.
BWrite unit tests only after deployment to avoid slowing down development.
CPlace all functions and their corresponding unit tests in a single notebook or script.
DSeparate functions into dedicated modules and place all unit tests in a separate test suite or notebook.
A Machine Learning Engineer is working with a Spark DataFrame that contains 100 million retail-transaction rows across thousands of stores. Each store needs its own demand-forecasting model, using the same scikit-learn pipeline. The engineer wants to train and apply these models in parallel for every store without collecting the data to the driver.
Which approach accomplishes this?
AUse rdd.mapPartitions() to iterate through each store and apply the model logic in Python.
BUse groupBy("store_id").applyInPandas() to train and apply the model per group using a Pandas UDF.
CUse pyspark.pandas to call .groupby("store_id").apply() and train the model on each group.
DConvert the DataFrame to a Pandas DataFrame using .toPandas() and loop through each store locally.
A Machine Learning Engineer requires a continuous deployment pipeline for models hosted on Databricks Model Serving. The deployment automation must run after a model is trained and registered with MLflow. Its objective is to deploy the latest model version from the MLflow Model Registry only when the model can satisfy the company’s strict latency requirement (P95 < 300ms) while handling production traffic.
How can the engineer confirm that new models satisfy the latency requirement when they are served in production?
AA/B test the latest model with Databricks Model Serving so that the latest model receives 5% of production traffic and the current model receives the rest. Use inference tables to calculate P95 latency and verify it is less than 300ms.
BServe the latest model on Databricks Model Serving and use a load testing client to generate requests at the production request rate. Use the load testing client to calculate P95 latency and verify it is less than 300ms.
CUse the MLflow Get Run API to retrieve the model metrics from MLflow Tracking and verify that the model_latency metric is less than 300ms.
DUse the MLflow Get Run API to retrieve the model metrics from MLflow Tracking and verify that the inference_latency metric is less than 300ms.
A machine learning engineer wants to log and deploy a model as an MLflow pyfunc model. They have custom preprocessing that must be performed on feature variables before fitting the model or generating predictions with it. They choose to wrap this preprocessing in a custom model class, ModelWithPreprocess, where preprocessing occurs when fit and predict are called. They then log the fitted ModelWithPreprocess model as a pyfunc model.
Which of the following is a benefit of this approach when the logged pyfunc model is loaded for downstream deployment?
AThe pyfunc model can be used to deploy models in a parallelizable fashion
BThe same preprocessing logic will automatically be applied when calling fit
CThe same preprocessing logic will automatically be applied when calling predict
DThis approach has no impact when loading the logged pyfunc model for downstream deployment
EThere is no longer a need for pipeline-like machine learning objects
Which of the following statements defines label drift?
ALabel drift is when there is a change in the distribution of the predicted target given by the model
BNone of these describe label drift
CLabel drift is when there is a change in the distribution of an input variable
DLabel drift is when there is a change in the relationship between input variables and target variables
ELabel drift is when there is a change in the distribution of a target variable
A Data Scientist is training machine-learning models in a notebook and must track varying parameters, a key performance metric named team_metric, and a summary graphic using MLflow. They find that tracking is not working as expected and review their logging code. For the logging portion of their code, they have:
Why is the code not logging according to their requirements?
Alog_artifact is only possible for raw data not files.
BThey needed to use mlflow.log_metrics for the metrics_dict instead of mlflow.log_params for metrics to be displayed in the UI metrics tab.
Clog_artifact requires a path to a directory, not a file, so nothing was tracked for the image.
DSklearn-flavor MLflow models do not support metric tracking.
A machine learning engineer has implemented numeric-drift monitoring by examining trends in the summary statistics of input variables. However, the engineer’s stakeholders want a more robust monitoring solution.
Which of the following can provide a more robust drift-monitoring solution for numeric feature variables?
ANone of these can provide more robust drift monitoring than summary statistics
BStatistical tests
COversampling
DCorrelations
A Data Scientist must build a sales-forecasting model that predicts each store’s sales monthly. They have been asked to configure Lakehouse Monitoring so the model can be assessed daily for potential accuracy metrics, such as RMSE. To do this, they will first configure Lakehouse Monitoring with the Inference profile type.
What is the next step in this process?
ASet the problem type to Classification and ensure that Change Data Feed is configured on the monitored tables.
BSet the problem type to Regression and appropriately set the Label Column, Prediction Column, and Model ID Column.
CSet the problem type to Regression and set the Baseline Table.
DSet the problem type to Classification and set the Baseline Table.
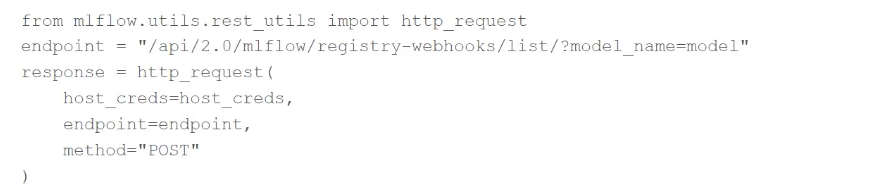
A machine learning engineer needs to view all active MLflow Model Registry Webhooks for a particular model. They are using this code block:
Which change must the machine learning engineer make to this code block for it to successfully complete the task?
AThere are no necessary changes
BReplace list with view in the endpoint URL
CReplace POST with GET in the call to http_request
DReplace list with webhooks in the endpoint URL
EReplace POST with PUT in the call to http_request
A machine learning engineer is migrating a machine learning pipeline to use Databricks Machine Learning. They have programmatically identified the best run from an MLflow Experiment and saved its URI in the model_uri variable and its Run ID in the run_id variable. They have also established that the model was logged under the name "model".
The machine learning engineer now wants to register that model in the MLflow Model Registry with the name "best_model".
Which of the following code lines can they use to register the model in the MLflow Model Registry?
Which of the following Feature Store Client fs operations can return a Spark DataFrame for a data set associated with a Feature Store table?
Afs.create_table
Bfs.write_table
Cfs.get_table
DThere is no way to accomplish this task with fs
Efs.read_table
A Machine Learning Engineer is training a large-scale gradient-boosting model with SparkML on a cluster of machines. After several iterations, the training job fails because memory overflows on one executor node. Cluster resources are limited to executor nodes that each have 16 CPU cores and 64 GB of RAM. The engineer wants to continue model training without changing hyperparameters or reducing the dataset size. They understand Spark’s architecture well and want to leverage its advantages.
Which approach will enable the Machine Learning Engineer to resolve this issue?
AIncrease the number of executor nodes and replicate the entire model on each node, then implement data parallelism to train on different mini-batches simultaneously.
BIncrease the number of executor nodes and implement data parallelism by partitioning the dataset across executors so each node trains the model on a subset of data.
CIncrease the number of executor nodes and replicate the entire model on each node, then apply model parallelism to train different parts of the model in parallel.
DIncrease the number of executor nodes and implement model parallelism by splitting the gradient boosting model across executors so each node trains a part of the model.
A Machine Learning Engineer is developing a script to score a large batch of customer data with a SparkML RandomForestClassificationModel registered in Unity Catalog. They want to follow commonly accepted coding best practices for this model.
Which approach best meets their needs?
ALoad the model using MLflow’s mlflow.spark.load_model method, then perform batch predictions with RandomForestClassificationModel.transform().
BProvide the URI of the registered Unity Catalog model to Spark’s DataFrame predict method to perform batch predictions.
CLoad the model using MLflow’s mlflow.pyfunc.spark_udf method, then perform batch predictions with RandomForestClassificationModel.transform().
DProvide the URI of the registered Unity Catalog model to the Databricks ai_query function to perform batch predictions.
A data scientist needs to track runs for a random forest model. Across each run, the scientist changes the number of trees and the maximum tree depth in the forest.
They write the following code:
Which Python object type must params be an instance of?
Aarray
BPySpark DataFrarne
Cdict
Dlist
A Data Scientist is building a fraud-detection model with a massive, imbalanced dataset of more than 100 terabytes. They selected SparkML’s Logistic Regression and must optimize its hyperparameters. Because of the dataset’s size and the need for robust evaluation, they are evaluating strategies for hyperparameter tuning and model selection within the Spark ecosystem. They require the most computationally and time-efficient method to tune the SparkML Logistic Regression model and assess its performance.
Which approach accomplishes this?
AImplementing a custom grid search using nested loops in PySpark, training the model on the full dataset for each combination, and evaluating with MulticlassClassificationEvaluator.
BUtilizing SparkML’s CrossValidator with a ParamGridBuilder and a BinaryClassificationEvaluator for distributed processing.
CExporting the dataset to a single machine, converting it to a Pandas DataFrame, and then using scikit-learn’s GridSearchCV for hyperparameter tuning and evaluation.
DManually trying different hyperparameter combinations and evaluating the model using BinaryClassificationEvaluator on a small, local sample of the data.
A machine learning engineer needs to load data from the first version of a Delta table at a location path.
Which of the following code lines can be used to complete this task?




Community Discussion