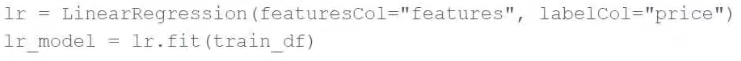Certified Machine Learning Associate Practice Exam — Free Online
A data scientist has a Spark DataFrame spark_df. They want to create a new Spark DataFrame that contains only the rows from spark_df where the value in column price is greater than 0.
Which of the following code blocks will accomplish this task?
Which of the following statements describes a Spark ML estimator?
AAn estimator is a hyperparameter grid that can be used to train a model
BAn estimator chains multiple algorithms together to specify an ML workflow
CAn estimator is a trained ML model which turns a DataFrame with features into a DataFrame with predictions
DAn estimator is an algorithm which can be fit on a DataFrame to produce a Transformer
EAn estimator is an evaluation tool to assess to the quality of a model
A data scientist wants to tune a set of hyperparameters for a machine learning model. They have wrapped a Spark ML model in the objective function objective_function and they have defined the search space search_space.
As a result, they have the following code block:
Which of the following changes do they need to make to the above code block in order to accomplish the task?
AChange SparkTrials() to Trials()
BReduce num_evals to be less than 10
CChange fmin() to fmax()
DRemove the trials=trials argument
ERemove the algo=tpe.suggest argument
A data scientist has a Spark DataFrame spark_df. They want to create a new Spark DataFrame that contains only the rows from spark_df where the value in column discount is less than or equal 0.
Which of the following code blocks will accomplish this task?
Aspark_df.loc[:,spark_df["discount"] <= 0]
Bspark_df[spark_df["discount"] <= 0]
Cspark_df.filter (col("discount") <= 0)
Dspark_df.loc(spark_df["discount"] <= 0, :]
A data scientist is utilizing MLflow Autologging to automatically track their machine learning experiments. After completing a series of runs for the experiment experiment_id, the data scientist wants to identify the run_id of the run with the best root-mean-square error (RMSE).
Which of the following lines of code can be used to identify the run_id of the run with the best RMSE in experiment_id?
A
B
C
D
Question 6
Model Deployment
0
Question 7
Databricks Machine Learning
Question 8
Model Development
Question 9
Data Processing
Question 10
Data Processing
Question 11
Data Processing
Question 12
Databricks Machine Learning
Question 13
Data Processing
Question 14
Databricks Machine Learning
Question 15
Model Development
Question 16
Data Processing
Question 17
Data Processing
Question 18
Model Development
Question 19
Data Processing
Question 20
Model Development
Question 21
Model Development
Question 22
Data Processing
Question 23
Data Processing
Question 24
Model Deployment
Question 25
Model Development
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ad
Want a break from the ads?
Become a Supporter and enjoy a completely ad-free experience, plus unlock Learn Mode, Exam Mode, AstroTutor AI, and more.
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
Ask AstroTutor
0
A data scientist has defined a Pandas UDF function predict to parallelize the inference process for a single-node model:
They have written the following incomplete code block to use predict to score each record of Spark DataFrame spark_df:
Which of the following lines of code can be used to complete the code block to successfully complete the task?
Apredict(*spark_df.columns)
BmapInPandas(predict)
Cpredict(Iterator(spark_df))
DmapInPandas(predict(spark_df.columns))
Epredict(spark_df.columns)
A machine learning engineer has created a Feature Table new_table using Feature Store Client fs. When creating the table, they specified a metadata description with key information about the Feature Table. They now want to retrieve that metadata programmatically.
Which of the following lines of code will return the metadata description?
AThere is no way to return the metadata description programmatically.
Bfs.create_training_set("new_table")
Cfs.get_table("new_table").description
Dfs.get_table("new_table").load_df()
Efs.get_table("new_table")
A health organization is developing a classification model to determine whether or not a patient currently has a specific type of infection. The organization's leaders want to maximize the number of positive cases identified by the model.
Which of the following classification metrics should be used to evaluate the model?
ARMSE
BPrecision
CArea under the residual operating curve
DAccuracy
ERecall
In which of the following situations is it preferable to impute missing feature values with their median value over the mean value?
AWhen the features are of the categorical type
BWhen the features are of the boolean type
CWhen the features contain a lot of extreme outliers
DWhen the features contain no outliers
EWhen the features contain no missing values
An organization is developing a feature repository and is electing to one-hot encode all categorical feature variables. A data scientist suggests that the categorical feature variables should not be one-hot encoded within the feature repository.
Which of the following explanations justifies this suggestion?
AOne-hot encoding is not supported by most machine learning libraries.
BOne-hot encoding is dependent on the target variable’s values which differ for each application.
COne-hot encoding is computationally intensive and should only be performed on small samples of training sets for individual machine learning problems.
DOne-hot encoding is not a common strategy for representing categorical feature variables numerically.
EOne-hot encoding is a potentially problematic categorical variable strategy for some machine learning algorithms.
A machine learning engineer is trying to scale a machine learning pipeline by distributing its feature engineering process.
Which of the following feature engineering tasks will be the least efficient to distribute?
AOne-hot encoding categorical features
BTarget encoding categorical features
CImputing missing feature values with the mean
DImputing missing feature values with the true median
ECreating binary indicator features for missing values
A data scientist is developing a machine learning pipeline using AutoML on Databricks Machine Learning.
Which of the following steps will the data scientist need to perform outside of their AutoML experiment?
AModel tuning
BModel evaluation
CModel deployment
DExploratory data analysis
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
Aimport pyspark.pandas as psdf = ps.DataFrame(spark_df)
Bimport pyspark.pandas as psdf = ps.to_pandas(spark_df)
Cspark_df.to_sql()
Dimport pandas as pddf = pd.DataFrame(spark_df)
Espark_df.to_pandas()
Which of the following is a benefit of using vectorized pandas UDFs instead of standard PySpark UDFs?
AThe vectorized pandas UDFs allow for the use of type hints
BThe vectorized pandas UDFs process data in batches rather than one row at a time
CThe vectorized pandas UDFs allow for pandas API use inside of the function
DThe vectorized pandas UDFs work on distributed DataFrames
EThe vectorized pandas UDFs process data in memory rather than spilling to disk
A machine learning engineer is converting a decision tree from sklearn to Spark ML. They notice that they are receiving different results despite all of their data and manually specified hyperparameter values being identical.
Which of the following describes a reason that the single-node sklearn decision tree and the Spark ML decision tree can differ?
ASpark ML decision trees test every feature variable in the splitting algorithm
BSpark ML decision trees automatically prune overfit trees
CSpark ML decision trees test more split candidates in the splitting algorithm
DSpark ML decision trees test a random sample of feature variables in the splitting algorithm
ESpark ML decision trees test binned features values as representative split candidates
A data scientist has replaced missing values in their feature set with each respective feature variable’s median value. A colleague suggests that the data scientist is throwing away valuable information by doing this.
Which of the following approaches can they take to include as much information as possible in the feature set?
AImpute the missing values using each respective feature variable’s mean value instead of the median value
BRefrain from imputing the missing values in favor of letting the machine learning algorithm determine how to handle them
CRemove all feature variables that originally contained missing values from the feature set
DCreate a binary feature variable for each feature that contained missing values indicating whether each row’s value has been imputed
ECreate a constant feature variable for each feature that contained missing values indicating the percentage of rows from the feature that was originally missing
Which of the Spark operations can be used to randomly split a Spark DataFrame into a training DataFrame and a test DataFrame for downstream use?
ATrainValidationSplit
BDataFrame.where
CCrossValidator
DTrainValidationSplitModel
EDataFrame.randomSplit
A data scientist wants to efficiently tune the hyperparameters of a scikit-learn model. They elect to use the Hyperopt library's fmin operation to facilitate this process. Unfortunately, the final model is not very accurate. The data scientist suspects that there is an issue with the objective_function being passed as an argument to fmin.
They use the following code block to create the objective_function:
Which of the following changes does the data scientist need to make to their objective_function in order to produce a more accurate model?
AAdd test set validation process
BAdd a random_state argument to the RandomForestRegressor operation
CRemove the mean operation that is wrapping the cross_val_score operation
DReplace the r2 return value with -r2
EReplace the fmin operation with the fmax operation
A data scientist is using Spark ML to engineer features for an exploratory machine learning project.
They decide they want to standardize their features using the following code block:
Upon code review, a colleague expressed concern with the features being standardized prior to splitting the data into a training set and a test set.
Which of the following changes can the data scientist make to address the concern?
AUtilize the MinMaxScaler object to standardize the training data according to global minimum and maximum values
BUtilize the MinMaxScaler object to standardize the test data according to global minimum and maximum values
CUtilize a cross-validation process rather than a train-test split process to remove the need for standardizing data
DUtilize the Pipeline API to standardize the training data according to the test data's summary statistics
EUtilize the Pipeline API to standardize the test data according to the training data's summary statistics
A machine learning engineer would like to develop a linear regression model with Spark ML to predict the price of a hotel room. They are using the Spark DataFrame train_df to train the model.
The Spark DataFrame train_df has the following schema:
The machine learning engineer shares the following code block:
Which of the following changes does the machine learning engineer need to make to complete the task?
AThey need to call the transform method on train_df
BThey need to convert the features column to be a vector
CThey do not need to make any changes
DThey need to utilize a Pipeline to fit the model
EThey need to split the features column out into one column for each feature
A data scientist uses 3-fold cross-validation and the following hyperparameter grid when optimizing model hyperparameters via grid search for a classification problem:
Hyperparameter 1: [2, 5, 10]
Hyperparameter 2: [50, 100]
Which of the following represents the number of machine learning models that can be trained in parallel during this process?
A3
B5
C6
D18
A data scientist is wanting to explore summary statistics for Spark DataFrame spark_df. The data scientist wants to see the count, mean, standard deviation, minimum, maximum, and interquartile range (IQR) for each numerical feature.
Which of the following lines of code can the data scientist run to accomplish the task?
Aspark_df.summary ()
Bspark_df.stats()
Cspark_df.describe().head()
Dspark_df.printSchema()
Espark_df.toPandas()
A data scientist is wanting to explore the Spark DataFrame spark_df. The data scientist wants visual histograms displaying the distribution of numeric features to be included in the exploration.
Which of the following lines of code can the data scientist run to accomplish the task?
Aspark_df.describe()
Bdbutils.data(spark_df).summarize()
CThis task cannot be accomplished in a single line of code.
Dspark_df.summary()
Edbutils.data.summarize (spark_df)
A machine learning engineer is trying to perform batch model inference. They want to get predictions using the linear regression model saved at the path model_uri for the DataFrame batch_df. batch_df has the following schema: customer_id STRING
The machine learning engineer runs the following code block to perform inference on batch_df using the linear regression model at model_uri:
In which situation will the machine learning engineer’s code block perform the desired inference?
AWhen the Feature Store feature set was logged with the model at model_uri
BWhen all of the features used by the model at model_uri are in a Spark DataFrame in the PySpark
CWhen the model at model_uri only uses customer_id as a feature
DThis code block will not perform the desired inference in any situation.
EWhen all of the features used by the model at model_uri are in a single Feature Store table
A data scientist uses 3-fold cross-validation when optimizing model hyperparameters for a regression problem. The following root-mean-squared-error values are calculated on each of the validation folds:
• 10.0
• 12.0
• 17.0
Which of the following values represents the overall cross-validation root-mean-squared error?