Certified Generative AI Engineer Associate Practice Exam — Free
Save question
A Generative AI Engineer is testing parameters to configure an agent in Mosaic Agent Framework. However, they are having difficulty getting the agent to return relevant information with the following configuration:
Which error is responsible for the issue?
AThe prompt does not parse the user's input vars
BThe prompt does not set the retriever schema
CThe prompt does not list available agents for the LLM to call
DThe prompt is not wrapped in ChatModel
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Governance
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Assembling and Deploying Applications
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ4
Governance
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ5
Data Preparation
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
A Generative AI Engineer is building an LLM application that interacts with users to deliver personalized movie recommendations.
Given the possibility of malicious user inputs, which technique would be most effective for safeguarding the application?
AReduce the time that the users can interact with the LLM
BIncrease the amount of compute that powers the LLM to process input faster
CAsk the LLM to remind the user that the input is malicious but continue the conversation with the user
DImplement a safety filter that detects any harmful inputs and ask the LLM to respond that it is unable to assist
A Generative AI Engineer is developing a RAG application to answer employee questions about company policies.
What steps are required to build and deploy this RAG application?
AIngest documents from a source -> Index the documents and saves to Vector Search -> User submits queries against an LLM -> LLM retrieves relevant documents -> Evaluate model -> LLM generates a response -> Deploy it using Model Serving
BUser submits queries against an LLM -> Ingest documents from a source -> Index the documents and save to Vector Search -> LLM retrieves relevant documents -> LLM generates a response -> Evaluate model -> Deploy it using Model Serving
CIngest documents from a source -> Index the documents and save to Vector Search -> Evaluate model -> Deploy it using Model Serving -> User submits queries against an LLM -> LLM retrieves relevant documents -> LLM generates a response
DIngest documents from a source -> Index the documents and save to Vector Search -> User submits queries against an LLM -> LLM retrieves relevant documents -> LLM generates a response -> Evaluate model -> Deploy it using Model Serving
A Generative AI Engineer is developing a production-ready LLM system that responds directly to customers. The solution uses the Foundation Model API through provisioned throughput. They are concerned that the LLM might produce a toxic or otherwise unsafe response. They also want to accomplish this with the least effort.
Which approach accomplishes this?
AAsk users to report unsafe responses
BHost Llama Guard on Foundation Model API and use it to detect unsafe responses.
CAdd some LLM calls to their chain to detect unsafe content before returning text
DAdd a regex expression on inputs and outputs to detect unsafe responses.
A Generative AI Engineer is creating a RAG application that will depend on context retrieved from source documents currently stored as PDFs. These PDFs may include both text and images. They want to build the solution with the fewest lines of code.
Which Python package should be used to extract text from the source documents?
Aflask
Bbeautifulsoup
Cunstructured
Dnumpy
QuestionQ6
Data Preparation
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ7
Design Applications
QuestionQ8
Application Development
QuestionQ9
Design Applications
QuestionQ10
Governance
QuestionQ11
Evaluation and Monitoring
QuestionQ12
Application Development
QuestionQ13
Data Preparation
QuestionQ14
Data Preparation
QuestionQ15
Assembling and Deploying Applications
QuestionQ16
Design Applications
QuestionQ17
Governance
QuestionQ18
Governance
QuestionQ19
Evaluation and Monitoring
QuestionQ20
Governance
QuestionQ21
Governance
QuestionQ22
Evaluation and Monitoring
QuestionQ23
Application Development
QuestionQ24
Assembling and Deploying Applications
QuestionQ25
Design Applications
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
A Generative AI Engineer is building a RAG system for their company to support internal document Q&A on structured HR policies, but the returned answers are often incomplete and unstructured. The retriever appears not to return all relevant context. The Generative AI Engineer has tried different embedding and response-generation LLMs, but results did not improve.
Which TWO options could improve response quality?
Choose two
AAdd the section header as a prefix to chunks
BSplit the document by sentence
CUse a larger embedding model
DIncrease the document chunk size
EFine tune the response generation model
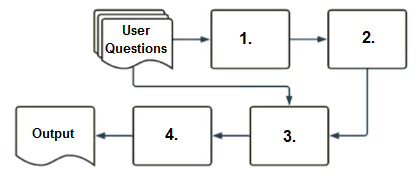
A company operates a typical customer-facing, RAG-enabled chatbot on its website.
Using the diagram above as a reference, select the correct sequence of components that a user’s questions pass through before the final output is returned.
C1.response-generating LLM, 2.vector search, 3.context-augmented prompt, 4.embedding model
D1.response-generating LLM, 2.context-augmented prompt, 3.vector search, 4.embedding model
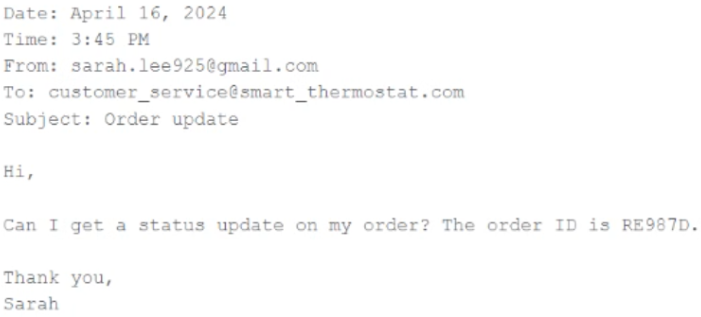
A Generative AI Engineer wants an LLM to parse and extract the following information: date, sender email, and order ID. The output must be formatted as JSON. Here is a sample email:
They need a prompt that extracts and returns the required information in JSON with the highest level of output accuracy.
Which prompt accomplishes this?
AYou will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in a human-readable format.
BYou will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
CYou will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format. Here’s an example: {"date":"April 16, 2024", "sender_email":"[email protected]", "order_id":"RE987D"}
DYou will receive customer emails and need to extract date, sender email, and order IYou should return the date, sender email, and order ID information in JSON format.
A Generative AI Engineer must design an LLM pipeline for multi-stage reasoning that uses external tools. To do this effectively, the LLM needs to plan and adapt its actions while carrying out complex reasoning tasks.
Which approach accomplishes this?
ATrain the LLM to generate a single, comprehensive response without interacting with any external tools, relying solely on its pre-trained knowledge.
BUse a Chain-of-Thought (CoT) prompting technique to guide the LLM through a series of reasoning steps, then manually input the results from external tools for the final answer.
CImplement a framework like ReAct, which allows the LLM to generate reasoning traces and perform task-specific actions that leverage external tools if necessary.
DEncourage the LLM to make multiple API calls in sequence without planning or structuring the calls, allowing the LLM to decide when and how to use external tools spontaneously.
A Generative AI Engineer is developing a system that will answer questions about news topics that are currently unfolding. Accordingly, it retrieves information from several sources, including articles and social-media posts. They are concerned that toxic social-media posts could cause the system to produce toxic outputs.
Which guardrail will limit toxic outputs?
AReduce the amount of context items the system will include in consideration for its response.
BUse only approved social media and news accounts to prevent unexpected toxic data from getting to the LLM.
CLog all LLM system responses and perform a batch toxicity analysis monthly.
DImplement rate limiting.
A Generative Al Engineer is developing a system that will answer questions about the latest stock-news articles.
Which option will NOT help ensure that the outputs are relevant to financial news?
AImplement a comprehensive guardrail framework that includes policies for content filters tailored to the finance sector.
BIncrease the compute to improve processing speed of questions to allow greater relevancy analysis
CImplement a profanity filter to screen out offensive language.
DIncorporate manual reviews to correct any problematic outputs prior to sending to the users
A Generative AI Engineer interacts with an instruction-following LLM trained on customer calls that inquire about product availability. The LLM must return “Success” when the product is available and “Fail” when it is not.
Which prompt enables the engineer to correctly obtain call-classification labels?
AYou are a helpful assistant that reads customer call transcripts. Walk through the transcript and think step-by-step if the customer’s inquiries are addressed successfully. Answer “Success” if yes; otherwise, answer “Fail”.
BYou will be given a customer call transcript where the customer asks about product availability. Classify the call as “Success” if the product is available and “Fail” if the product is unavailable.
CYou will be given a customer call transcript where the customer asks about product availability. The outputs are either “Success” or “Fail”. Format the output in JSON, for example: {"call_id": "123", "label": "Succes"}.
DYou will be given a customer call transcript. Answer “Success” if the customer call has been resolved successfully. Answer “Fail” if the call is redirected or if the question is not resolved.
A Generative AI Engineer has developed scalable PySpark code to ingest unstructured PDF documents and split them into chunks in preparation for storage in a Databricks Vector Search index. At present, the dataframe has two columns: the original filename as a string and an array of text chunks from that document.
Which set of steps should the Generative AI Engineer take to store the chunks in a format ready for ingestion by Databricks Vector Search?
AUse PySpark’s autoloader to apply a UDF across all chunks, formatting them in a JSON structure for Vector Search ingestion.
BFlatten the dataframe to one chunk per row, create a unique identifier for each row, and enable change feed on the output Delta table.
CUtilize the original filename as the unique identifier and save the dataframe as is.
DCreate a unique identifier for each document, flatten the dataframe to one chunk per row and save to an output Delta table.
A Generative AI Engineer needs to build an LLM application that can understand medical documents, including recently published ones. They want to choose an open model available on Hugging Face’s model hub.
Which step is the most appropriate for selecting an LLM?
APick any model in the Mistral family, as Mistral models are good with all types of use cases
BSelect a model based on the highest number of downloads, as this indicates popularity, reliability, and general suitability
CSelect a model that is most recently uploaded, as this indicates the model is the newest and highly likely to be the most performant
DCheck for the model and training data description to identify if the model is trained on any medical data.
A Generative AI Engineer has built an LLM application using the pay-per-token Foundation Model API. Now that the application is ready for deployment, they want to ensure that the model endpoint can handle high volumes of incoming production requests.
What should the Generative AI Engineer consider?
ASwitch to using External Models instead
BThrottle the incoming batch of requests manually to avoid rate limiting issues
CChange to a model with a fewer number of parameters in order to reduce hardware constraint issues
DDeploy the model using provisioned throughput as it comes with performance guarantees
A Generative AI Engineer is developing an LLM-based application with a critical transcription (speech-to-text) task. Application speed is essential to its success.
Which open Generative AI model should be used?
ADBRX
BMPT-30B-Instruct
CLlama-2-70b-chat-hf
Dwhisper-large-v3 (1.6B)
A Generative AI Engineer is building a conversational chatbot, based on a large language model (LLM), to help users with insurance-related inquiries. To keep the chatbot focused and comply with company policy, it must not answer questions about politics. Instead, for political inquiries, it should return this standard message:
> “Sorry, I cannot answer that. I am a chatbot that can only answer questions around insurance.”
Which type of framework should be implemented to address this?
ASafety Guardrail
BSecurity Guardrail
CContextual Guardrail
DCompliance Guardrail
A Generative AI Engineer is deploying a customer-facing, fine-tuned LLM to the company’s public website. Because the company made a large investment in fine-tuning this model and the tuning data is proprietary, they are concerned about model inversion attacks.
Which Databricks AI Security Framework (DASF) risk-mitigation strategies below are most relevant to this scenario?
Choose two
AImplement AI guardrails to allow users to configure and enforce compliance
BLeverage Databricks access control lists (ACLs) to configure permissions for accessing models
CUse secure model features with Databricks Feature Store
DApply attribute-based access controls (ABAC) to limit unauthorized access
A Generative AI Engineer is creating a chatbot for a gaming company to engage users on its platform while they play online video games.
Which metric would help increase user engagement and retention on the platform?
ARandomness
BDiversity of responses
CLack of relevance
DRepetition of responses
All of the following are Python APIs used to query Databricks foundation models. When working in an interactive notebook, which library does not automatically use the current session credentials?
AOpenAI client
BREST API via requests library
CMLflow Deployments SDK
DDatabricks Python SDK
A Generative AI Engineer is tasked with improving RAG quality by addressing inflammatory outputs.
Which action would be most effective for mitigating offensive text outputs?
AIncrease the frequency of upstream data updates
BInform the user of the expected RAG behavior
CRestrict access to the data sources to a limited number of users
DCurate upstream data properly that includes manual review before it is fed into the RAG system
Which indicator should be considered when evaluating the safety of LLM outputs through qualitative assessment of responses for a translation use case?
AThe ability to generate responses in code
BThe similarity to the previous language
CThe latency of the response and the length of text generated
DThe accuracy and relevance of the responses
A Generative AI Engineer must build an LLM application that excels at code generation. They need to choose a model specifically trained for generating code.
Which model would most likely provide the best out-of-the-box results?
ACodeLlama-34b-Instruct-hf
BMixtral-8x7B-v0.1
CLlama-2-70b-hf
Dmpt-7b-8k-instruct
A Generative AI Engineer has already trained an LLM on Databricks, and it is now ready to be deployed.
Which of the following steps correctly describes the easiest process for deploying a model on Databricks?
ALog the model as a pickle object, upload the object to Unity Catalog Volume, register it to Unity Catalog using MLflow, and start a serving endpoint
BLog the model using MLflow during training, directly register the model to Unity Catalog using the MLflow API, and start a serving endpoint
CSave the model along with its dependencies in a local directory, build the Docker image, and run the Docker container
DWrap the LLM’s prediction function into a Flask application and serve using Gunicorn
A Generative AI Engineer is building an LLM-powered application that requires access to current news articles and stock prices.
The design requires using stock prices stored in Delta tables and locating the latest relevant news articles through internet search. How should the Generative AI Engineer design the LLM system?
AUse an LLM to summarize the latest news articles and lookup stock tickers from the summaries to find stock prices.
BQuery the Delta table for volatile stock prices and use an LLM to generate a search query to investigate potential causes of the stock volatility.
CDownload and store news articles and stock price information in a vector store. Use a RAG architecture to retrieve and generate at runtime.
DCreate an agent with tools for SQL querying of Delta tables and web searching, provide retrieved values to an LLM for generation of response.

Community Discussion