Certified Data Engineer Professional Practice Exam — Free Online
QuestionQ1
Cost & Performance Optimisation
Save question
A data engineer runs a groupBy aggregation on a massive user-activity log, grouping by user_id. A small number of users have millions of records, resulting in task skew and long execution times.
Which technique will resolve the skew in this aggregation?
AIncrease the Spark driver memory and retry.
BFilter out the skewed users before the aggregation
CUse salting by adding a random prefix to skewed keys before aggregation, then aggregate again after removing the prefix.
DUse reduceByKey instead of groupBy to avoid shuffles.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ2
Developing Code for Data Processing using Python and SQL
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ3
Data Governance
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ4
Data Governance
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ6
Ensuring Data Security and Compliance
0
Community Discussion
No comments yet. Be the first to start the discussion!
It's free
100% of the questions are free for all users. No strings attached.
Developing Code for Data Processing using Python and SQLData Ingestion & AcquisitionData Transformation, Cleansing, and QualityData Sharing and FederationMonitoring and AlertingCost & Performance OptimisationEnsuring Data Security and ComplianceData GovernanceDebugging and DeployingData Modelling
A junior data engineer must build a streaming data pipeline using DataFrame df that performs a grouped aggregation. The pipeline must calculate average humidity and average temperature for every non-overlapping five-minute interval. Incremental state data must be retained for 10 minutes to accommodate late-arriving data.
Choose the response that correctly fills the blank in the code block to finish this task.
AwithWatermark("event_time", "10 minutes")
BawaitArrival("event_time", "10 minutes")
Cawait("event_time + ‘10 minutes'")
DslidingWindow("event_time", "10 minutes")
EdelayWrite("event_time", "10 minutes")
A small United States-based company has recently engaged a consulting firm in India to implement several new data-engineering pipelines that will power artificial-intelligence applications. All company data is stored in regional cloud storage in the United States.
The company’s workspace administrator is unsure where the Databricks workspace used by the contractors should be deployed.
Assuming all data-governance considerations have been addressed, which statement correctly guides this decision?
ADatabricks runs HDFS on cloud volume storage; as such, cloud virtual machines must be deployed in the region where the data is stored.
BDatabricks workspaces do not rely on any regional infrastructure; as such, the decision should be made based upon what is most convenient for the workspace administrator.
CCross-region reads and writes can incur significant costs and latency; whenever possible, compute should be deployed in the same region the data is stored.
DDatabricks notebooks send all executable code from the user’s browser to virtual machines over the open internet; whenever possible, choosing a workspace region near the end users is the most secure.
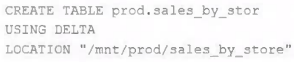
The data architect has required that every table in the Lakehouse be configured as an external (also called “unmanaged”) Delta Lake table.
Which approach ensures this requirement is satisfied?
AWhen a database is being created, make sure that the LOCATION keyword is used.
BWhen the workspace is being configured, make sure that external cloud object storage has been mounted.
CWhen data is saved to a table, make sure that a full file path is specified alongside the USING DELTA clause.
DWhen tables are created, make sure that the UNMANAGED keyword is used in the CREATE TABLE statement.
The security team is investigating whether the Databricks secrets module can be used to connect to an external database.
After testing the code with all Python variables defined as strings, they upload the password to the secrets module and set the correct permissions for the currently active user. They then update their code as follows, leaving every other variable unchanged.
Which statement explains what will occur when the preceding code runs?
AThe connection to the external table will fail; the string "REDACTED" will be printed.
BAn interactive input box will appear in the notebook; if the right password is provided, the connection will succeed and the encoded password will be saved to DBFS.
CAn interactive input box will appear in the notebook; if the right password is provided, the connection will succeed and the password will be printed in plain text.
DThe connection to the external table will succeed; the string value of password will be printed in plain text.
EThe connection to the external table will succeed; the string "REDACTED" will be printed.
QuestionQ7
Debugging and Deploying
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ8
Monitoring and Alerting
QuestionQ9
Debugging and Deploying
QuestionQ10
Cost & Performance Optimisation
QuestionQ11
Ensuring Data Security and Compliance
QuestionQ12
Monitoring and Alerting
QuestionQ13
Ensuring Data Security and Compliance
QuestionQ14
Data Ingestion & Acquisition
QuestionQ15
Data Governance
QuestionQ16
Developing Code for Data Processing using Python and SQL
QuestionQ17
Data Ingestion & Acquisition
QuestionQ18
Data Transformation, Cleansing, and Quality
QuestionQ19
Developing Code for Data Processing using Python and SQL
QuestionQ20
Data Modelling
QuestionQ21
Ensuring Data Security and Compliance
QuestionQ22
Monitoring and Alerting
QuestionQ23
Data Transformation, Cleansing, and Quality
QuestionQ24
Ensuring Data Security and Compliance
QuestionQ25
Cost & Performance Optimisation
QuestionQ26
Cost & Performance Optimisation
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
BStructured Streaming can process continuous data streams, while Lakeflow Spark Declarative Pipelines cannot.
CLakeflow Spark Declarative Pipelines manage the orchestration of multi-stage pipelines automatically, while Structured Streaming requires external orchestration for complex dependencies.
DLakeflow Spark Declarative Pipelines can write to Delta Lake format while structured streaming cannot.
A Databricks user who is new to the platform is attempting to troubleshoot lengthy execution times for pipeline logic they are developing. Currently, the user executes code one cell at a time and uses display() calls to verify that, as new transformations are added to an operation, the code produces logically correct results. To measure average execution time, the user runs every cell interactively several times.
Which adjustment will provide a more accurate measurement of how the code is likely to perform in production?
AScala is the only language that can be accurately tested using interactive notebooks; because the best performance is achieved by using Scala code compiled to JARs, all PySpark and Spark SQL logic should be refactored.
BThe only way to meaningfully troubleshoot code execution times in development notebooks Is to use production-sized data and production-sized clusters with Run All execution.
CProduction code development should only be done using an IDE; executing code against a local build of open source Spark and Delta Lake will provide the most accurate benchmarks for how code will perform in production.
DCalling display() forces a job to trigger, while many transformations will only add to the logical query plan; because of caching, repeated execution of the same logic does not provide meaningful results.
EThe Jobs UI should be leveraged to occasionally run the notebook as a job and track execution time during incremental code development because Photon can only be enabled on clusters launched for scheduled jobs.
All records from an Apache Kafka producer are ingested into one Delta Lake table with this schema:
key BINARY, value BINARY, topic STRING, partition LONG, offset LONG, timestamp LONG
Five unique topics are being ingested. Only the registration topic contains Personally Identifiable Information (PII). The company wants to restrict access to PII. It also wants to retain records containing PII in this table for only 14 days after initial ingestion. However, it wants to retain non-PII records indefinitely.
Which of the following solutions meets these requirements?
AAll data should be deleted biweekly; Delta Lake's time travel functionality should be leveraged to maintain a history of non-PII information.
BData should be partitioned by the registration field, allowing ACLs and delete statements to be set for the PII directory.
CBecause the value field is stored as binary data, this information is not considered PII and no special precautions should be taken.
DSeparate object storage containers should be specified based on the partition field, allowing isolation at the storage level.
EData should be partitioned by the topic field, allowing ACLs and delete statements to leverage partition boundaries.
When scheduling Structured Streaming jobs in production, which configuration automatically recovers from query failures while keeping costs low?
ACluster: New Job Cluster;Retries: Unlimited;Maximum Concurrent Runs: Unlimited
BCluster: New Job Cluster;Retries: None;Maximum Concurrent Runs: 1
Which statement describes a primary technical challenge of ensuring consistent PII masking across every node in large-scale, distributed Databricks batch and streaming pipelines?
APII masking is only required for direct identifiers.
BDynamic data masking is applied only at rest, so it does not affect query performance.
CMasking functions must be standardized and managed through Unity Catalog, with enforcement applied across all relevant datasets to avoid any data inconsistency.
DNative masking in Databricks automatically synchronizes with all downstream external Databricks systems.
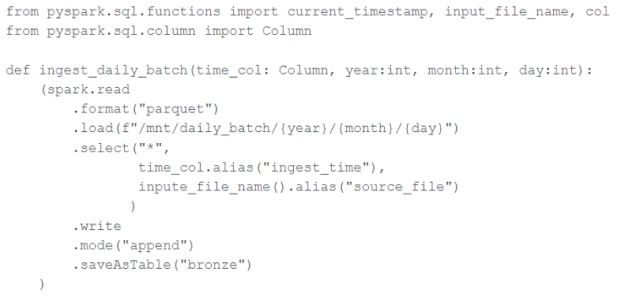
A nightly job ingests data into a Delta Lake table using the following code:
The next pipeline step requires a function that returns an object that can be used to manipulate new records that have not yet been processed into the next table in the pipeline.
Which code snippet completes this function definition?
The data architect has required that every table in the Lakehouse be configured as an external (also called “unmanaged”) Delta Lake table.
Which approach will ensure this requirement is satisfied?
AWhen a database is being created, make sure that the LOCATION keyword is used.
BWhen configuring an external data warehouse for all table storage, leverage Databricks for all ELT.
CWhen data is saved to a table, make sure that a full file path is specified alongside the Delta format.
DWhen tables are created, make sure that the EXTERNAL keyword is used in the CREATE TABLE statement.
EWhen the workspace is being configured, make sure that external cloud object storage has been mounted.
A junior data-engineering team member is investigating language interoperability in Databricks notebooks. The desired result of the code below is to register a view containing all sales made in countries from the continent of Africa that are present in the geo_lookup table.
Before the code is run, SHOW TABLES in the current database shows that it contains only two tables: geo_lookup and sales.
Which statement accurately describes the result of running these command cells sequentially in an interactive notebook?
ABoth commands will succeed. Executing show tables will show that countries_af and sales_af have been registered as views.
BCmd 1 will succeed. Cmd 2 will search all accessible databases for a table or view named countries_af: if this entity exists, Cmd 2 will succeed.
CCmd 1 will succeed and Cmd 2 will fail. countries_af will be a Python variable representing a PySpark DataFrame.
DBoth commands will fail. No new variables, tables, or views will be created.
ECmd 1 will succeed and Cmd 2 will fail. countries_af will be a Python variable containing a list of strings.
A data engineer is ingesting JSON files from cloud object storage by using Databricks Auto Loader. The source folder may occasionally receive large data files, risking an overwhelmed stream. To ensure predictable micro-batch sizes, the team wants to throttle ingestion at 1 GB based on the volume of data scanned, irrespective of the number of files.
Which Auto Loader configuration should the data engineer use to accomplish this?
AConfigure cloudFiles.maxBytesPerTrigger with 1 GB to place a limit.
BConfigure cloudFiles.maxSizePerTrigger with 1 GB to place a limit.
CConfigure cloudFiles.maxFilesPerTrigger and estimate the average file size to approximate a size-based throttle of 1 GB.
DConfigure cloudFiles.maxPartitionBytes with 1GB to limit data in each partition.
A data engineering team needs to implement a tagging system for its tables as part of an automated ETL process and must apply tags to Unity Catalog tables programmatically.
Which SQL command programmatically adds tags to a table?
DSET TAGS FOR table_name AS (‘key1’ = ‘value1’, ‘key2’ = ‘value2’)
Which statement describes the general programming model used by Spark Structured Streaming?
AStructured Streaming leverages the parallel processing of GPUs to achieve highly parallel data throughput.
BStructured Streaming is implemented as a messaging bus and is derived from Apache Kafka.
CStructured Streaming relies on a distributed network of nodes that hold incremental state values for cached stages.
DStructured Streaming models new data arriving in a data stream as new rows appended to an unbounded table.
A junior data engineer is implementing logic for a Lakehouse table named silver_device_recordings. The source data has 100 unique fields within a highly nested JSON structure.
The silver_device_recordings table will be used downstream to support several production monitoring dashboards and a production model. Currently, 45 of the 100 fields are used by at least one of these applications.
The data engineer is determining the best approach to schema declaration given the data’s highly nested structure and numerous fields.
Which of the following correctly states information about Delta Lake and Databricks that could affect their decision-making process?
AThe Tungsten encoding used by Databricks is optimized for storing string data; newly-added native support for querying JSON strings means that string types are always most efficient.
BBecause Delta Lake uses Parquet for data storage, data types can be easily evolved by just modifying file footer information in place.
CHuman labor in writing code is the largest cost associated with data engineering workloads; as such, automating table declaration logic should be a priority in all migration workloads.
DBecause Databricks will infer schema using types that allow all observed data to be processed, setting types manually provides greater assurance of data quality enforcement.
ESchema inference and evolution on Databricks ensure that inferred types will always accurately match the data types used by downstream systems.
The data engineering team has configured a job to handle customer requests to be forgotten (to have their data deleted). All user data requiring deletion is stored in Delta Lake tables with the default table settings.
The team has chosen to process all deletions from the prior week as a batch job at 1am every Sunday. This job runs for less than one hour in total. Each Monday at 3am, another batch job runs a series of VACUUM commands on all Delta Lake tables across the organization.
The compliance officer has recently become aware of Delta Lake's time-travel functionality and is concerned it could permit ongoing access to deleted data.
Assuming that all deletion logic is implemented correctly, which statement correctly addresses this concern?
ABecause the VACUUM command permanently deletes all files containing deleted records, deleted records may be accessible with time travel for around 24 hours.
BBecause the default data retention threshold is 24 hours, data files containing deleted records will be retained until the VACUUM job is run the following day.
CBecause Delta Lake time travel provides full access to the entire history of a table, deleted records can always be recreated by users with full admin privileges.
DBecause Delta Lake's delete statements have ACID guarantees, deleted records will be permanently purged from all storage systems as soon as a delete job completes.
EBecause the default data retention threshold is 7 days, data files containing deleted records will be retained until the VACUUM job is run 8 days later.
A platform-team lead is responsible for automating attribution of SQL Warehouse usage to individual teams. The requirement is to identify SQL warehouse usage at the individual-user level and produce a daily report to share with an executive team that includes leaders from every business unit.
How should the platform lead create an automated report that can be shared daily?
AUse the system tables to capture the audit and billing usage data and share the queries with the executive team. This enables the executives to execute the query and see the latest results any time.
BUse the system tables to capture the audit and billing usage data and create a dashboard with daily refresh schedules and shared with the executive team.
CRestrict users from running any SQL query unless they provide all the query details so that the attribution can be calculated and shared with the executive team.
DLet the users run the SQL query and then directly report the usage to the executives. The ownership of the SQL warehouse usage will be with the individual teams.
A Delta Lake table named customer_churn_params in the Lakehouse is used by the machine learning team for churn prediction. The table holds customer information derived from several upstream sources. At present, the data engineering team populates this table nightly by overwriting it with the currently valid values derived from upstream data sources.
Immediately after every successful update, the data engineering team wants to determine the difference between the new table version and its preceding version.
Given the current implementation, which method can be used?
AExecute a query to calculate the difference between the new version and the previous version using Delta Lake’s built-in versioning and lime travel functionality.
BParse the Delta Lake transaction log to identify all newly written data files.
CParse the Spark event logs to identify those rows that were updated, inserted, or deleted.
DExecute DESCRIBE HISTORY customer_churn_params to obtain the full operation metrics for the update, including a log of all records that have been added or modified.
EUse Delta Lake’s change data feed to identify those records that have been updated, inserted, or deleted.
The data engineering team has been assigned to configure connections to an external database for which Databricks has no supported native connector. The external database already has data security configured through group membership. These groups directly map to user groups already created in Databricks that represent different teams within the company.
A new login credential has been created for every group in the external database. The Databricks Utilities Secrets module will be used to make these credentials available to Databricks users.
Assuming all credentials are configured correctly on the external database and group membership is properly configured in Databricks, which statement describes how teams can be granted the minimum necessary access to use these credentials?
ANo additional configuration is necessary as long as all users are configured as administrators in the workspace where secrets have been added.
B"Read" permissions should be set on a secret key mapped to those credentials that will be used by a given team.
C"Read" permissions should be set on a secret scope containing only those credentials that will be used by a given team.
D"Manage" permissions should be set on a secret scope containing only those credentials that will be used by a given team.
Given the following PySpark code in a Databricks notebook:
The data engineer sees in the Query Profile that the scan operator for filtered_df reads nearly all files despite the filter being applied.
What is the likely reason for ineffective data skipping?
AThe Delta table lacks optimization that enables dynamic file pruning.
BThe filter condition involves a data type that is excluded from data skipping support.
CThe filter is executed only after the full data scan, which prevents data skipping from taking place.
DThe event_date column is outside the table’s partitioning and Z-ordering scheme.
Which statement characterizes Delta Lake Auto Compaction?
AAn asynchronous job runs after the write completes to detect if files could be further compacted; if yes, an OPTIMIZE job is executed toward a default of 1 GB.
BBefore a Jobs cluster terminates, OPTIMIZE is executed on all tables modified during the most recent job.
COptimized writes use logical partitions instead of directory partitions; because partition boundaries are only represented in metadata, fewer small files are written.
DData is queued in a messaging bus instead of committing data directly to memory; all data is committed from the messaging bus in one batch once the job is complete.
EAn asynchronous job runs after the write completes to detect if files could be further compacted; if yes, an OPTIMIZE job is executed toward a default of 128 MB.





Community Discussion