Apache Spark Architecture and ComponentsUsing Spark SQLDeveloping Apache Spark™ DataFrame/DataSet API ApplicationsTroubleshooting and Tuning Apache Spark DataFrame API Applications.Structured StreamingUsing Spark Connect to deploy applicationsUsing Pandas API on Spark
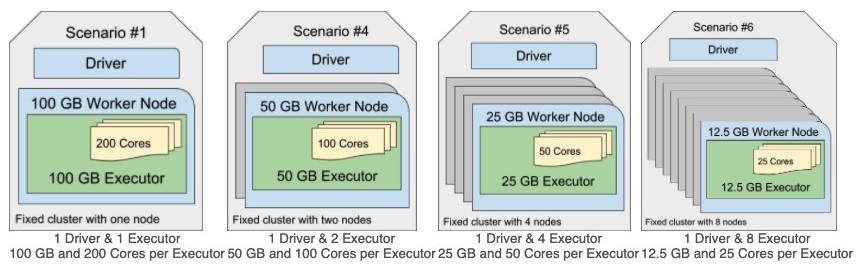
A Spark developer is building a Spark application to monitor task performance throughout a cluster. One application requirement is to track the maximum processing time for tasks on every worker node and consolidate this data on the driver for further analysis.
Which technique should the developer use to accomplish this?
AUse an RDD action like reduce () to compute the maximum time.
BUse an accumulator to record the maximum time on the driver.
CBroadcast a variable to share the maximum time among workers.
DConfigure the Spark UI to automatically collect maximum times.
A data engineer is working on a Spark job that must join multiple DataFrames. Given this code snippet that performs the joins:
AThe code will fail because only one broadcast join can be performed at a time.
BThe code will fail because the second join condition (df2.id == df3.id) is not correct. The correct condition should be (df1.id == df3.id).
CThe code will work correctly and perform two broadcast joins simultaneously to join df1 with df2 and then the result with df3.
DThe code will result in an error because the broadcast function is used incorrectly, df2 and df3 must be explicitly broadcasted before performing the joins.
The code block below contains a logical error that results in inefficiency. It is intended to efficiently perform a broadcast join of DataFrame storesDF and the much larger DataFrame employeesDF using key column storeId. Identify the logical error.
Code block:
storesDF.join(broadcast(employeesDF), "storeId")
AThe larger DataFrame employeesDF is being broadcasted rather than the smaller DataFrame storesDF.
BThere is never a need to call the broadcast() operation in Apache Spark 3.
CThe entire line of code should be wrapped in broadcast() rather than just DataFrame employeesDF.
DThe broadcast() operation will only perform a broadcast join if the Spark property spark.sql.autoBroadcastJoinThreshold is manually set.
EOnly one of the DataFrames is being broadcasted rather than both of the DataFrames.
A data engineer is developing a Spark application containing two DataFrames:
DataFrame A holds detailed transaction records from the last year and is 128 GB in size.
DataFrame B holds a lookup table of user details and is 1 GB in size.
For performance optimization, the developer chooses to use a broadcast join.
Which approach should the engineer use to choose the DataFrame to broadcast?
ADataFrame B should be broadcasted because it is smaller and will eliminate the need for shuffling itself.
BDataFrame B should be broadcasted because it is smaller and will eliminate the need for shuffling DataFrame A.
CDataFrame A should be broadcasted because it is larger and will eliminate the need for shuffling DataFrame B.
DDataFrame A should be broadcasted because it is smaller and will eliminate the need for shuffling itself.
QuestionQ6
Troubleshooting and Tuning Apache Spark DataFrame API Applications.
0
Community Discussion
No comments yet. Be the first to start the discussion!
QuestionQ7
Structured Streaming
QuestionQ8
Using Spark SQL
QuestionQ9
Troubleshooting and Tuning Apache Spark DataFrame API Applications.
QuestionQ10
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ11
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ12
Troubleshooting and Tuning Apache Spark DataFrame API Applications.
QuestionQ13
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ14
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ15
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ16
Troubleshooting and Tuning Apache Spark DataFrame API Applications.
QuestionQ17
Apache Spark Architecture and Components
QuestionQ18
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ19
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ20
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ21
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ22
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ23
Developing Apache Spark™ DataFrame/DataSet API Applications
QuestionQ24
Using Spark SQL
QuestionQ25
Developing Apache Spark™ DataFrame/DataSet API Applications
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Save question
0
Community Discussion
No comments yet. Be the first to start the discussion!
Ad
Want a break from the ads?
Go ad-free and unlock Learn Mode, Exam Mode, AstroTutor AI and every premium tool — everything you need to walk in prepared, and confident.
The code block below contains an error. It is intended to return the exact number of distinct values in the division column in DataFrame storesDF. Identify the error.
AThe approx_count_distinct() operation needs a second argument to set the rsd parameter to ensure it returns the exact number of distinct values.
BThere is no alias() operation for the approx_count_distinct() operation's output.
CThere is no way to return an exact distinct number in Spark because the data Is distributed across partitions.
DThe approx_count_distinct()operation is not a standalone function - it should be used as a method from a Column object.
EThe approx_count_distinct() operation cannot determine an exact number of distinct values in a column.
Which of the following code blocks writes the DataFrame storesDF to the file path filePath in JSON format?
AstoresDF.write.option("json").path(filePath)
BstoresDF.write.json(filePath)
CstoresDF.write.path(filePath)
DstoresDF.write(filePath)
EstoresDF.write().json(filePath)
A data scientist at a financial services company is working with a Spark DataFrame that contains transaction records. The DataFrame has millions of rows and includes columns for transaction_id, account_number, transaction_amount, and timestamp. Because of a source-system issue, some transactions were inadvertently recorded multiple times with identical data in every field. The data scientist must remove rows duplicated across all fields to ensure accurate financial reporting.
Which approach should the data scientist use to deduplicate the orders with PySpark?
The code block below includes an error. It is intended to return a new DataFrame resulting from a position-wise union between DataFrame storesDF and DataFrame acquiredStoresDF.
Aconcat(storesDF, acquiredStoresDF)
BstoresDF.unionByName(acquiredStoresDF)
Cunion(storesDF, acquiredStoresDF)
DunionAll(storesDF, acquiredStoresDF)
EstoresDF.union(acquiredStoresDF)
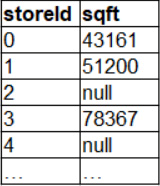
Which of the following code blocks returns a new DataFrame in which column sqft from DataFrame storesDF has its missing values replaced with the value 30,000?
A sample of DataFrame storesDF is shown below:
AstoresDF.na.fill(30000, Seq("sqft"))
BstoresDF.nafill(30000, col("sqft"))
CstoresDF.na.fill(30000, col("sqft"))
DstoresDF.fillna(30000, col("sqft"))
EstoresDF.na.fill(30000, "sqft")
Which of the following code blocks returns a new DataFrame resulting from a position-wise union of DataFrame storesDF and DataFrame acquiredStoresDF?
A@F.udf(T.IntegerType())def simple_udf(t: int) -> int:return t * 3.14159
B@F.udf(T.DoubleType())def simple_udf(t: float) -> float:return t * 3.14159
C@F.udf(T.DoubleType())def simple_udf(t: int) -> int:return t * 3.14159
D@F.udf(T.IntegerType())def simple_udf(t: float) -> float:return t * 3.14159
A data engineer is working with a dataset that contains 2 billion rows spread across 10 Spark partitions. The engineer must compute the approximate count of distinct users by the user_id field and also calculate the average transaction_amount. Both calculations must occur in a single transformation step to minimize shuffling.
Which set of Spark code accomplishes this goal while maintaining performance?
Cdf.creareOrReplaceTempView(“transactions”)spark.sql(“””SELECT -COUNT(DISTINCT user_id) AS approx._count_distinct,AVG(transaction_amount) AS average_transactionFROM transactions -“””).show()
Which of the following statements describes slots?
ASlots are the most coarse level of execution in the Spark execution hierarchy.
BSlots are resource threads that can be used for parallelization within a Spark application.
CSlots are resources that are used to run multiple Spark applications at once on a single cluster.
DSlots are the most granular level of execution in the Spark execution hierarchy.
ESlots are unique segments of data from a DataFrame that are split up by row.
The code block below has an error. It is intended to return a new DataFrame that results from an outer join between DataFrame storesDF and DataFrame employeesDF on the storeId column. Identify the error.
Code block:
storesDF.join(employeesDF, "storeId")
AThe default argument to the how parameter is "inner" – an additional argument of "outer" must be specified.
BThe key column storeId needs to be wrapped in the col() operation.
CThe key column storeId needs to be specified in an expression of both Data Frame columns like storesDF.storeId == employeesDF.storeId.
DThe key column storeId needs to be in a list like ["storeId"].
EThere is no DataFrame.join() operation – DataFrame.merge() should be used instead.
Which of the following code blocks returns a DataFrame sorted alphabetically by the division column?
AstoresDF.sort("division")
BstoresDF.orderBy(desc("division"))
CstoresDF.orderBy(col("division").desc())
DstoresDF.orderBy("division", ascending - true)
EstoresDF.sort(desc("division"))
Which of the following code blocks produces a new DataFrame from storesDF in which the storeId column is of type string?
A data scientist at an e-commerce company is working with user data obtained from its subscriber database and stored in a DataFrame named df_user. Before processing the data further, the data scientist wants to create another DataFrame, df_user_non_pii, containing only the non-PII columns. The PII columns in df_user are first_name, last_name, email, and birthdate.
Which code snippet can be used to meet this requirement?
The code block below must create a single-column DataFrame from the Scala list years, which consists of integers. Choose the response that correctly fills the numbered blanks in the code block to complete this task.
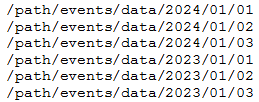
A data engineer must build an ingestion pipeline for a set of Parquet files that an upstream team delivers nightly. The data resides in a directory structure with the base path /path/events/data. The upstream team places daily data in the underlying subdirectories using the year/month/day convention.
Examples of the directory structure include:
Which of the following code snippets reads all data in the directory structure?

Community Discussion