Loading provider exams...
Loading provider exams...
Sign Up & unlock 100% of Exam Questions
No Strings Attached!
Updated
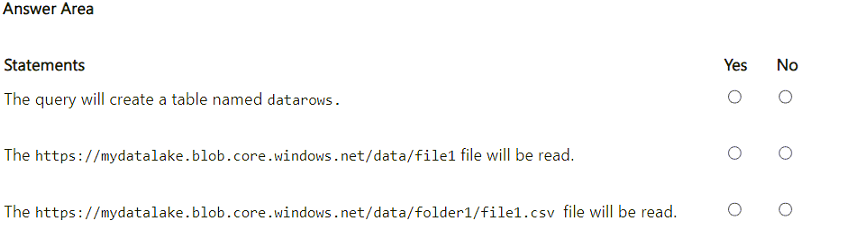
You have an Azure subscription that contains an Azure Synapse Analytics serverless SQL pool.
You run the following query in the pool.
SELECT *
FROM OPENROWSET(BULK 'https://mydatalake.blob.core.windows.net/data/**',
FORMAT = 'CSV') AS datarows;
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
This exam has 18 community-verified practice questions. Create a free account to access all questions, comments, and explanations.
Log In / Sign UpYou are designing the dimensions for a data warehouse in an Azure Synapse Analytics dedicated SQL pool.
You build a table by using the statement shown in the following exhibit.
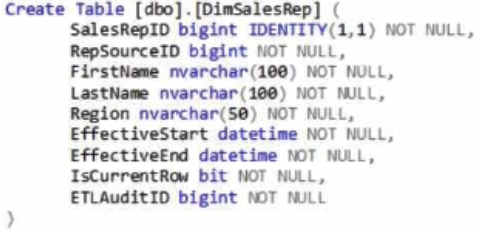
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the exhibit.
NOTE: Each correct selection is worth one point.

You have an Azure subscription that contains two Azure Synapse Analytics workspaces named Workspace1 and Workspace2.
You use Workspace1 to develop new artifacts. You use Workspace2 to store production versions of artifacts.
You need to implement continuous integration.
What should you do first in Synapse Studio?
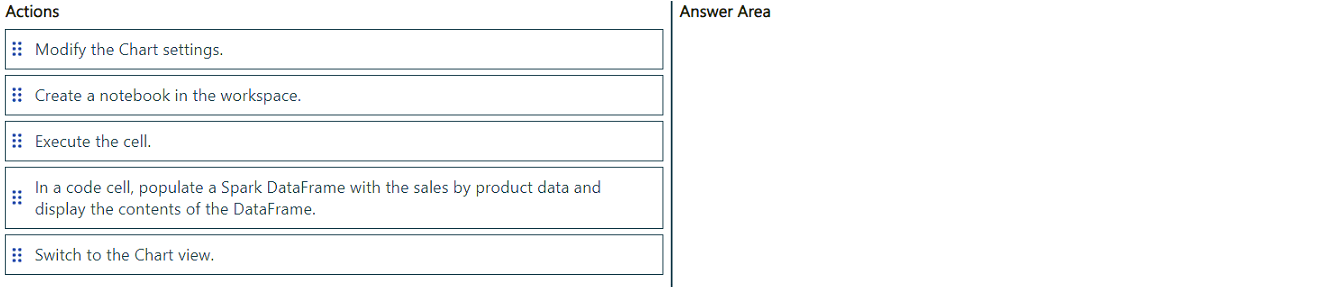
You have an Azure Data Lake Storage account named account1 and an Azure Synapse Analytics workspace that contains an Apache Spark pool named Pool1.
You use Pool1 to access sales data in account1.
You need to create a bar chart that displays sales by product. The solution must use PySpark and minimize development effort.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.
You have an Azure subscription that contains a Log Analytics workspace named Workspace1 and an Azure Synapse Analytics workspace named Workspace2. Workspace1 contains pipeline-run data.
You execute the following query against Workspace1.
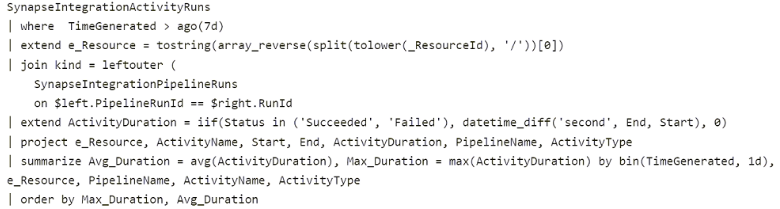
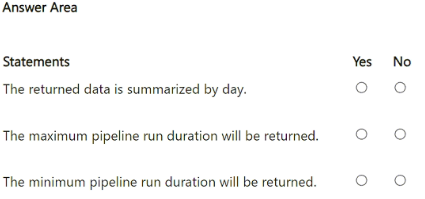
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
You have an Azure Stream Analytics job that reads data from an Azure event hub.
You need to evaluate whether the job processes data as quickly as the data arrives or cannot keep up.
Which metric should you review?
You have an Azure Cosmos DB account named account1.
You plan to create an Azure Synapse Analytics workspace named worskpace1.
You need to ensure that workspace1 and account1 connect over the Microsoft backbone network without using public endpoints. The solution must minimize administrative effort.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct answer is worth one point.

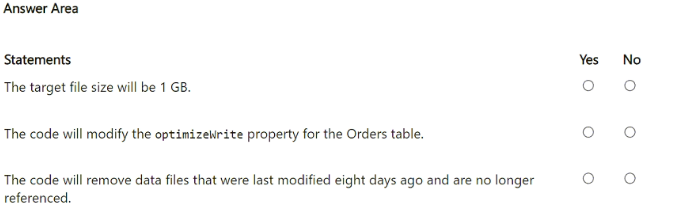
You have an Azure subscription that contains an Azure Synapse Analytics account and an Azure Data Lake Storage Gen2 account named storage1.storage1 contains a 20-TB Delta table.
You run the following Python code.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.